Boost Running with RXT4080: GPU Cloud Tips



Key Highlights
Introduction of Mixtral: Mixtral is now the most popular free open-source large language model.
Problems with running LLM using RTX4080: Insufficient display memory, Slow TTFT, and Huge cost.
How to fix these problems: Improve Mixtral’s performance, use multiple graphics cards, or use extended memory.
Advantages of using GPU Instances: higher scalability, lower cost, pay-as-you-go, and lower maintenance costs.
Related tutorials: A tutorial on running Mixtral locally and a tutorial on using GPU Instances.
Introduction
This blog will explore how to make the Mixtral family of products run better on RTX 4080 GPUs, a type of consumer hardware such as laptops. We’ll talk about managing memory and setting up GPUs to use its resources efficiently, including utilizing at least two GPUs with 16 GB of VRAM each for optimal performance. We’ll also compare running LLM models on your computer to using GPU instances, which may give you better performance by utilizing VRAM as a high-speed buffer for efficient loading and preventing performance issues.
Unlock the Power of the Mixtral Open-Source Model
Before unleashing the potential of Mixtral, people first need to know what Mixtral is. In addition, understanding the different versions of Mixtral will also help users choose the right hardware device according to different versions of LLM.
What is the Mixtral Model?
Mixtral is a free and open-source large-scale language model created by Mistral.ai. In the 2023 Imsys list, Mixtral 8x7b became one of the highest-rated LLM open-source models by users.
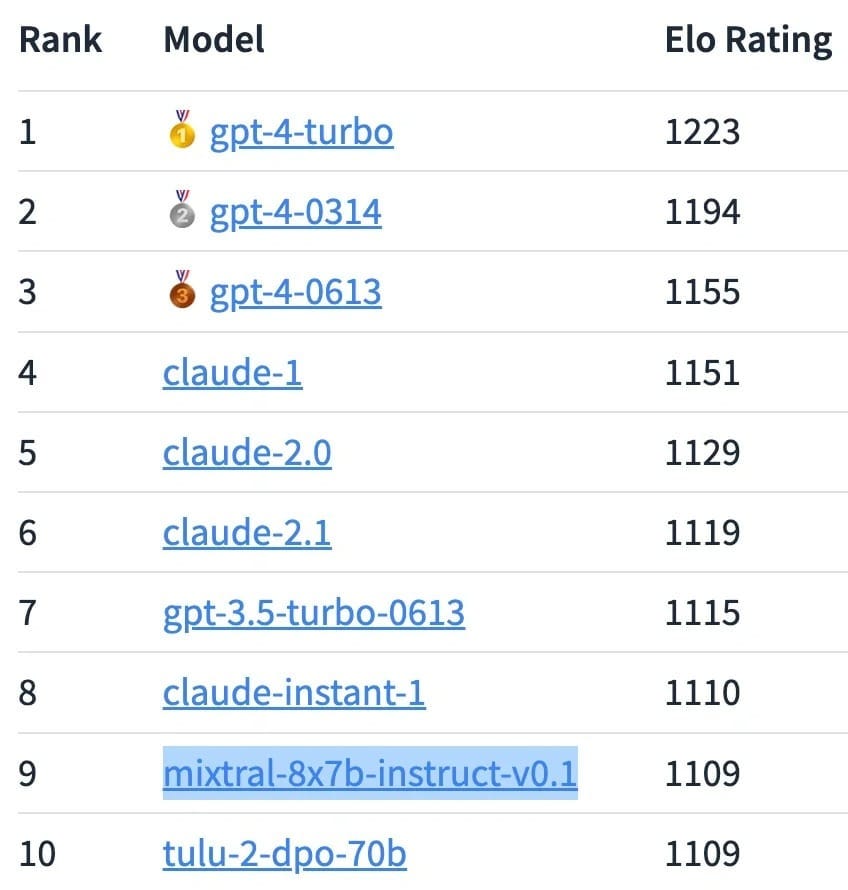
LLM ranking
It uses a method called Expert Sparse Blending (MoE), also known as a sparse mixture of experts. This is different from regular llm because not all parts of Mixtral are used simultaneously. Instead, only a few “expert” sections are activated depending on the task.
How many versions are there of Mistral?
By 2024, Mistral.ai has launched four free and open-source LLM models, as follows:
Mistral 7B
Mixtral 8x7B
Mixtral 8x22B
With the development of the Mixtral series products, the reasoning ability, multilingual ability, and mathematical coding ability of this series of products have been greatly improved.
However, these improvements also require users to use more memory and better perform. For example, the hardware requirements for running Mixtral 8x22b on a PC require a GPU with approximately 300GB of memory for this LLM model to run smoothly.
Mixtral running on 4080
Now some users choose to use RTX4080 to run Mixtral, For example, Slaghton successfully ran Mixtral 8x7b with two RTX4080s. However, due to the memory limitations of the local GPU, this LLM can only run at minimal productivity. In this case, the LLM can only generate about 7–8 tokens per second.
How do you run Mixtral 8x7b using local GPUs?
Video tutorial: Install Mixtral 8x7B Locally on Windows on Laptop
Step 1: You need a large enough computer space to run, so start cleaning your computer first!
Step 2: Install the necessary Python libraries and tools, such as TensorFlow, PyTorch, etc. These libraries and tools can be installed via pip or conda.
Step 3: Download the Mixtral 8x7B model file from the official channel. The model file is usually provided as a compressed package containing the weights and configuration files for the model.
Step 4: Unzip the downloaded model file to the specified directory.
Step 5: According to the configuration file of the model, set the necessary environment variables, such as the model path, device type (CPU/GPU), etc.
What happens when you run Mixtral with local RTX4080?
people trying to run LLM with a consumer-grade graphics card may encounter the following problems.
Insufficient display memory: The RXT4080 has a maximum display memory of 16GB, but it may take around 200–300GB to run Mixtral smoothly.
Slow TTFT: Based on the experience of several Reddit content publishers running Mistral 7b and Mixtral 8x7b using 4060,4080 and 4090. Using a consumer graphics card to run LLM model TTFT speeds could only reach 1t/ S — 8T /s.
Huge cost: These content publishers often use several graphics cards or external memory to run Mixtral. According to the price posted on Amazon’s website, an RTX4080 graphics card costs $999.
How to improve the performance of 4080 running Mixtral?
Fine-tuning the settings of LLM is very important for getting the best performance on the RTX 4080’s 16GB GPU memory. One key setting is ‘batch size.’ This setting defines how many input samples are processed at the same time. If you lower the batch size, it can reduce VRAM usage.1.
It is also a good idea to expand the memory of the 4080 graphics card with extended memory.
Use multiple graphics cards.
The future trends in running Mixtral
With the development of LLM, the computing power and display memory required for running LLM are increasing. The opportunity for an individual to run an LLM by using a consumer-grade graphics card is also becoming smaller and smaller. A new way to run LLM is becoming popular among LLM individuals and enterprises, and that is to run it using GPU Instance.
What is GPU Instances?
GPU instances are virtual machines or computing resources provided in a cloud computing environment that are equipped with graphics processing units (GPUs).
Application scenario:
Deep learning: Training neural network models require a lot of matrix operations, and the parallel processing capabilities of GPUs can significantly speed up training.
Graphics rendering: Used in game development, film and television production, and other fields to provide high-quality graphics output.
Scientific computing: Complex simulations and calculations in the fields of physics, chemistry, and biology.
GPU Instance VS local GPU
1. It is cheaper to use GPU Instances instead: The price of GPU instances that use RTX 4090 is less than 1 $/h. But according to Amazon, a local RTX4090 costs about $1,660.
Cost of GPU Instance
2. Higher scalability: Users of GPU Instances can dynamically adjust the number and performance of GPU instances based on demand with the click of a mouse.
3. Pay-as-you-go: Users can pay based on usage, with no upfront investment in hardware.
4. Lower maintenance costs: use of virtual GPU resources can not worry about hardware damage caused by the program not running.
How to use the GPU Cloud?
step 1: Go to the Novita.ai website and click Produce — GPU Instance
Novita.ai website page
**step 2:**Click Start Building Now

Novita.ai website page
step 3: Select the type of graphics card you need and the amount of memory you need and click Deploy.
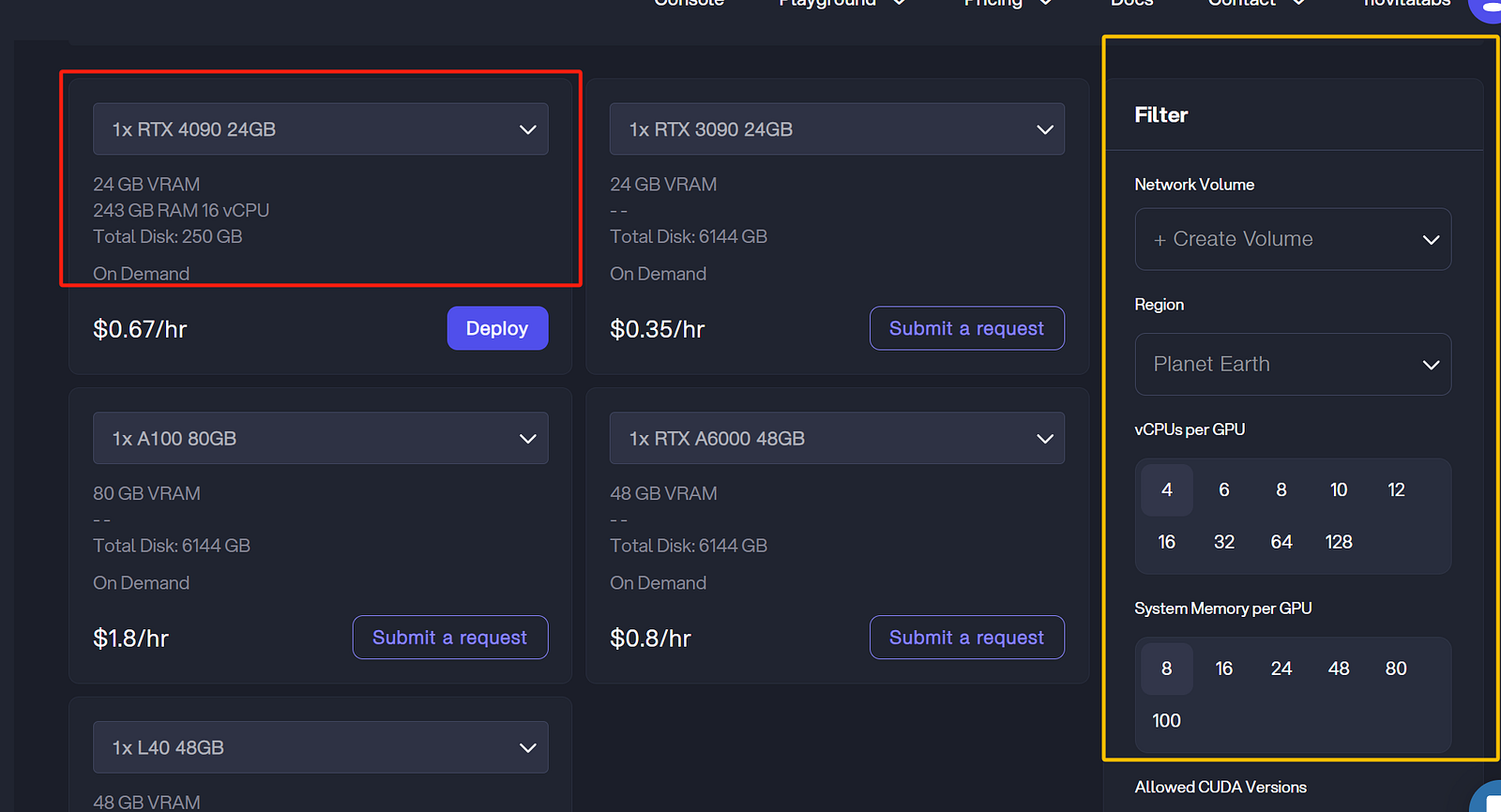
Novita.ai website page
For details about How to create a GPU instance, see How to Use Llama 3 on Novita AI GPU Instance
Frequently Asked Questions
How much RAM does Mixtral need?
Mixtral usually needs at least 8GB of RAM to work well. If your tasks are more complex, having more RAM can help. It is important to have enough RAM for Mixtral to run smoothly and to process tasks efficiently.
What GPU is needed for Mixtral 8x22B?
To use Mixtral 8x22B effectively, you need a powerful GPU. It’s best to have at least 48GB of VRAM. The NVIDIA A100 is a good option for getting the best performance from Mixtral.
How fast is Mistral 7B token generation?
Mistral 7B shows great token generation speeds. These speeds can change depending on your hardware and setup. On a high-end consumer GPU, like the RTX 4080, it usually generates between 10 to 20 tokens every second.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.