


Meta’s Llama 3.2 Vision takes a big step forward in multimodal AI, combining powerful image processing with advanced language understanding. This cutting-edge model unlocks exciting new possibilities for developers and businesses to explore. In this guide, we’ll take a closer look at what makes Llama 3.2 Vision so impressive—its architecture, features, real-world applications, and the tools available to help you get started. Along the way, we’ll focus on practical tips and technical insights to help you make the most of its capabilities.
Understanding Llama 3.2 Vision
Llama 3.2 Vision is part of Meta's latest iteration in the Llama series of large language models (LLMs), focusing on multimodal capabilities that integrate advanced image processing with language understanding. This model is designed to handle a wide range of tasks, from visual recognition and image reasoning to captioning and answering questions about images.
Explore Llama 3.2 11B Vision Instruct Now
One of the key features of Llama 3.2 Vision is its availability in different sizes, specifically the 11B and 90B models. These models are optimized to fit on edge and mobile devices, making them accessible to developers with limited compute resources. This flexibility allows for a broader range of applications and use cases, from mobile apps to enterprise-level systems.
The model's architecture is based on a modified Vision Transformer, which allows for efficient feature extraction from 16x16 pixel patches. This design supports high performance across various image resolutions and complexities, making it versatile for different types of visual data.
Llama 3.2 Vision comes in both base and instruction-tuned variants. The instruction-tuned models are particularly optimized for tasks such as visual recognition, image reasoning, captioning, and answering general questions about images. This makes them highly adaptable to various real-world scenarios and applications.
Key Architectural Advancements of Llama 3.2 Vision
Llama 3.2 Vision introduces several key architectural advancements that set it apart from its predecessors and other multimodal models:
Vision Encoder
At the core of Llama 3.2 Vision's visual processing capabilities is the Vision Encoder. Built on a sophisticated modified version of the Vision Transformer architecture, it implements parallel processing of 16x16 pixel patches. This approach enables more efficient feature extraction while maintaining high performance across varying image resolutions and complexities.
Vision Adapter
Llama 3.2 Vision integrates a vision adapter, consisting of a series of cross-attention layers. This adapter is separately trained and designed to seamlessly integrate with the pre-trained Llama 3.1 language model. By feeding image encoder representations into the core language model, the architecture effectively supports image recognition tasks.
Instruction Tuning
The instruction-tuned models within the Llama 3.2 Vision collection are optimized for a variety of visual tasks. This optimization allows them to excel in areas such as visual recognition, image reasoning, captioning, and answering general questions about images.
Scalability
The architecture supports different model sizes, from the smaller 11B to the larger 90B versions. This scalability ensures that developers can choose the most appropriate model for their specific use case and available resources.
Long Context Support
Llama 3.2 Vision supports long context lengths of up to 128K text tokens, allowing for more comprehensive and nuanced understanding of complex inputs.
High-Resolution Image Processing
The model can handle image resolutions up to 1120 x 1120 pixels, enabling detailed analysis of high-quality images.These architectural advancements contribute to Llama 3.2 Vision's impressive performance on common industry benchmarks, often outperforming many existing open-source and closed multimodal models.
Specifications and Performance
Llama 3.2 Vision models offer a range of specifications tailored for both edge and mobile devices, focusing on flexibility and performance:
Model Sizes: Llama 3.2 Vision models come in various sizes, including vision models with 11 billion and 90 billion parameters, and text-only models with 1 billion and 3 billion parameters.
Input Handling: The models support both text and image inputs, with long context lengths of up to 128K text tokens and image resolutions up to 1120 x 1120 pixels.
Optimization: The lightweight design is suitable for devices with limited computational resources. Additionally, NVIDIA optimization ensures efficient performance across a wide range of hardware, from powerful data center GPUs to low-power edge devices like NVIDIA Jetson.
Performance Metrics: The models offer low latency responses and high throughput for cost-efficient serving.In terms of benchmark performance, Llama 3.2 Vision has shown impressive results:
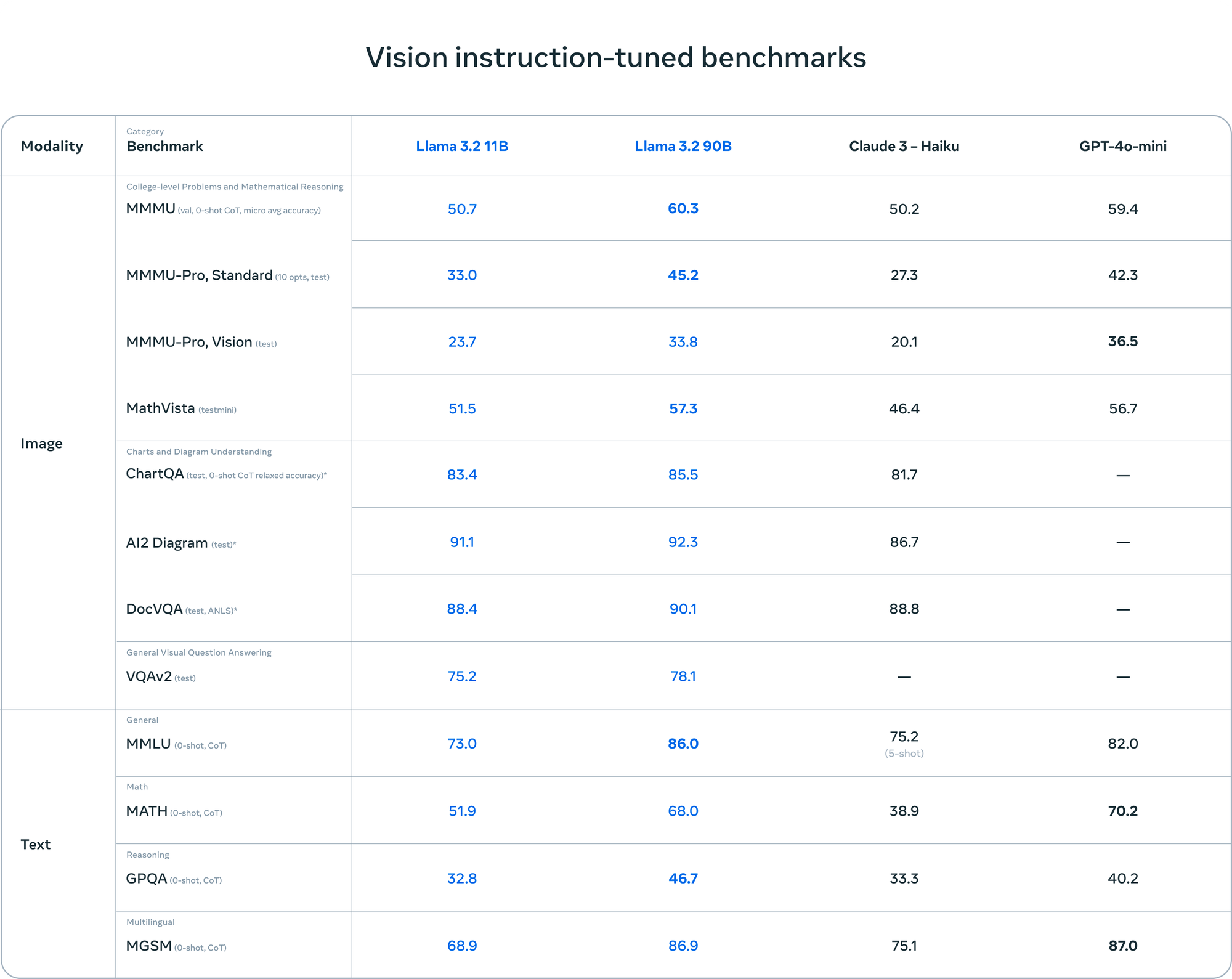
Source from Meta
These benchmarks demonstrate Llama 3.2 Vision's strengths in document-level understanding, visual question answering, and data extraction from charts. However, they also highlight areas for potential improvement, particularly in mathematical reasoning over visual data.For the lightweight models, the 3B version has shown particularly strong capabilities:
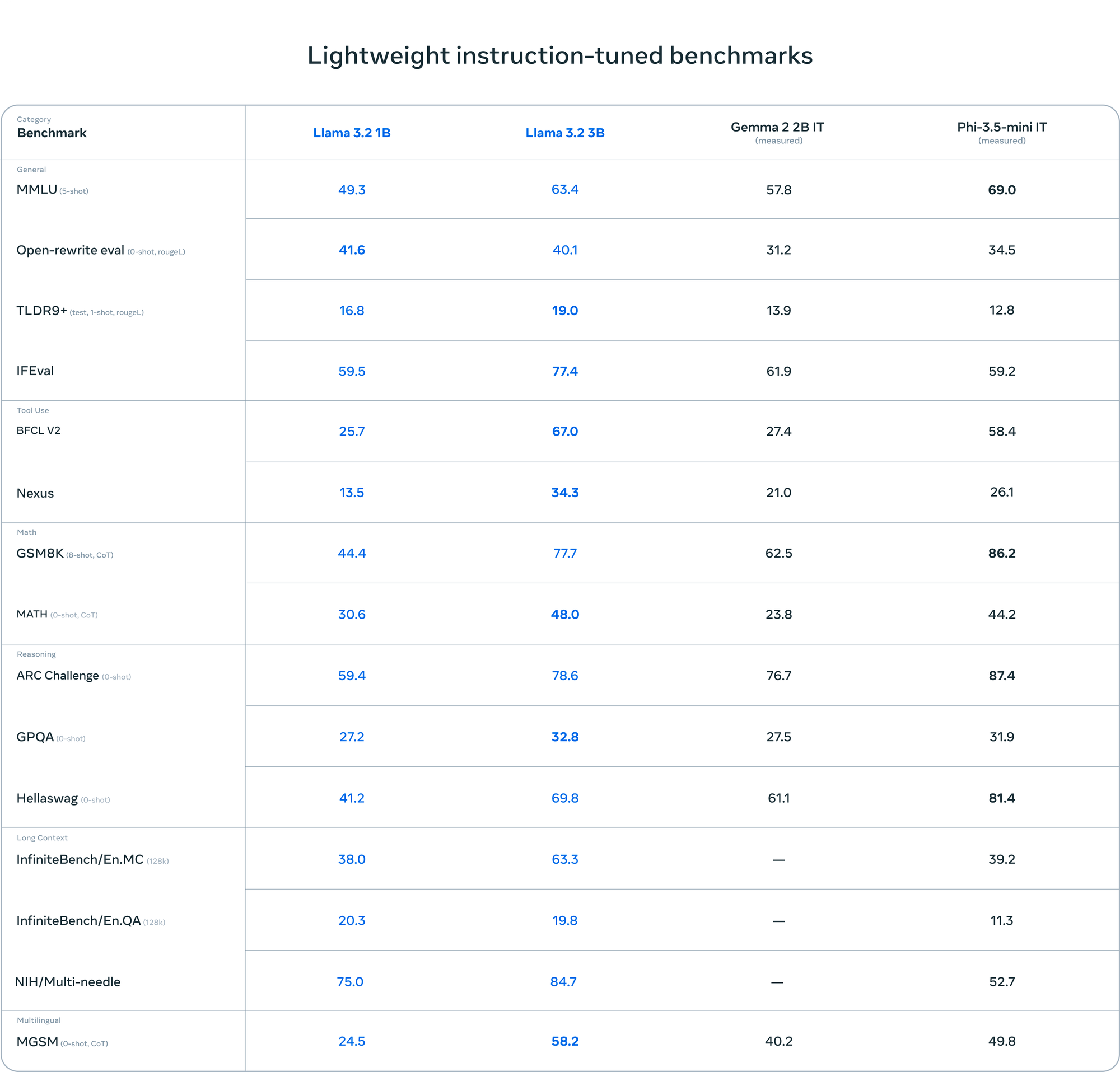
Source from Meta
Real-World Applications of Llama 3.2 Vision

Llama 3.2 Vision's advanced capabilities have paved the way for innovative applications across various industries. Here are some scenarios illustrating its practical use:
Healthcare
Imagine a busy emergency room where an AI-powered triage assistant, built on Llama 3.2 Vision, quickly analyzes patients' visible symptoms, medical charts, and X-rays. It prioritizes cases, suggesting immediate attention for a child with a suspected fracture while reassuring a patient with minor cuts. This AI assistant, similar to the Atlas system developed during Meta's Llama Impact Hackathon, helps reduce waiting times and improve resource allocation in A&E departments.
Retail and E-commerce
Picture a shopper using their smartphone to snap a photo of a stylish outfit they saw on the street. The Llama 3.2 Vision-powered app instantly identifies similar items available in nearby stores or online, even suggesting complementary accessories.
Environmental Conservation
Envision wildlife researchers using drones equipped with Llama 3.2 Vision to monitor endangered species in remote areas. The AI can identify and count animals, detect signs of poaching, and even assess vegetation health, all in real-time.
Education
Imagine a classroom where students point their tablets at complex diagrams in their textbooks. The Llama 3.2 Vision app instantly provides interactive explanations, 3D models, and additional resources, making learning more engaging and accessible.
Manufacturing and Quality Control
Picture a production line where Llama 3.2 Vision-enabled cameras inspect products at high speed, detecting even the tiniest defects that human eyes might miss. The system not only flags issues but also suggests possible causes and solutions, improving overall product quality. This application highlights the model's capability to process and analyze visual data rapidly, making it ideal for real-time industrial applications.
Explore Llama 3.2 11B Vision Instruct Now
Accessing Llama 3.2 Vision on Novita AI
Developers interested in leveraging Llama 3.2 Vision can access it through Novita AI. Novita AI provides access to Llama 3.2 11B Vision Instruct, offering a powerful and efficient version of the model for developers to integrate into their applications.
Model Access: Novita AI provides access to Llama 3.2 11B Vision Instruct, offering a powerful and efficient version of the model for developers to integrate into their applications.
Deployment Options: The models can be deployed in the cloud, which is suitable for applications requiring substantial computational resources. Edge deployment is ideal for scenarios needing low-latency responses or offline capabilities. Mobile deployment is perfect for on-device AI applications with limited resources.
Implementation Guides: Detailed documentation is available to help developers set up and use the models effectively. Step-by-step guides on platforms like Hugging Face provide clear instructions for model deployment.
API Integration: Novita AI's Quick Start guide offers developers a straightforward path to integrating Llama 3.2 Vision and other LLM APIs into their projects.
Conclusion
Llama 3.2 Vision represents a significant advancement in multimodal AI, offering powerful capabilities in visual and language understanding. Its flexible architecture, ranging from lightweight models to more comprehensive versions, makes it adaptable to various applications and deployment scenarios. As developers continue to explore and implement this technology, we can expect to see innovative solutions across multiple industries. With ongoing research and community contributions, Llama 3.2 Vision is poised to play a crucial role in shaping the future of AI-powered applications.
Frequently Asked Questions
What is Llama 3.2 Vision?
Llama 3.2 Vision is a multimodal AI model by Meta that integrates image processing with language understanding, suitable for various tasks like captioning and visual recognition.
Does Llama 3 have vision capabilities?
Yes, Llama 3.2 includes robust vision capabilities, enabling it to analyze images, answer questions about them, and generate captions.
Can Llama 3.2 generate an image?
No, Llama 3.2 Vision is focused on understanding and analyzing images rather than generating new images.
How to train Llama 3.2 Vision?
Training involves using large datasets for multimodal learning, applying techniques for image and text integration, usually requiring significant computational resources.
What is Llama 3.2 good for?
Llama 3.2 Vision excels in applications across healthcare, education, e-commerce, and manufacturing, including visual question answering, image captioning, and quality control.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading