




Key Highlights
we explored the latest benchmarks, evaluated the input and output token costs, assessed latency and throughput, and provide guidance on the best model choice for your needs.From this analysis we learn that:
General Knowledge Understanding: Qwen 2.5 (72b) performs better in MMLU scores.
Coding: Llama 3.3 (70b) performs better in HumanEval scores.
Math Problems: Qwen 2.5 (72b) performs better in MATH scores.
Multilingual Support: Qwen 2.5 (72b) performs better with more supported languages.
Price & Speed: Llama 3.3 70b excels in API and hardware requirements.
If you’re looking to evaluate the Llama 3.3 70b or Qwen 2.5 72b on your own use-cases — Novita AI can provider free trail.
Basic Introduction of Two Model’s Family
To begin our comparison, we first understand the fundamental characteristics of each model.
Qwen 2.5 : A Versatile Suite of Models
Qwen 2.5, developed by the Alibaba group, represents a significant advancement in the field of LLMs. This suite offers a range of models with parameters ranging from 0.5B to 72B, catering to diverse computational needs and applications. The Qwen 2.5 family includes specialized models, such as Qwen2.5-Coder and Qwen2.5-Math, designed to excel in specific domains. The key features of Qwen 2.5 include:
Training on an extensive dataset of 18 trillion tokens
Support for over 29 languages, enhancing its multilingual capabilities
Ability to generate long-form text with coherence and context
Proficiency in following complex instructions and managing structured data
Improved comprehensive general knowledge understanding (18% higher than the previous generation model)
Llama 3.3: Meta’s Efficient and Powerful LLM
In contrast, Llama 3.3, which was developed by Meta, is a 70B parameter model specifically designed for text-based tasks. The architecture and training methodology set it apart in several ways:
Optimized transformer architecture
Trained using supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF)
Incorporates 15 trillion tokens of publicly available data in its training
The proposed method employs grouped query attention (GQA) for improved inference scalability
Supports eight core languages with a focus on quality over quantity
Performance Comparison
Now that we’ve established the basic characteristics of each model, let’s delve into their performance across various benchmarks. This comparison will help illustrate their strengths in different areas.
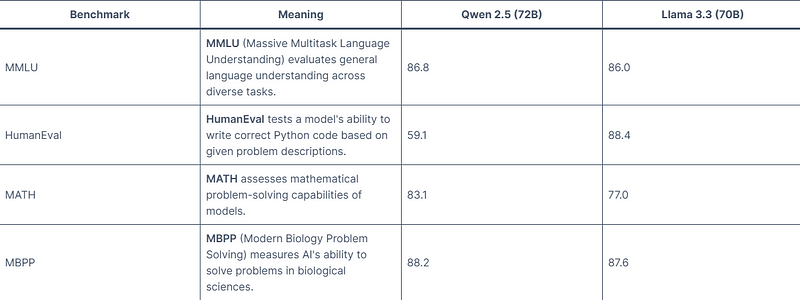
As we can see from this table, Llama 3.3 70b demonstrates particular strengths in coding tasks (HumanEval, MBPP) and instruction following (IFEval). In contrast, Qwen 2.5 72b demonstrated balanced performance across various domains, excelling in MMLU and MATH. If you would like to know more about the llama3.3 benchmark knowledge. You can view this article as follows: Llama 3.3 Benchmark: Key Advantages and Application Insights.
Resource Efficiency
When evaluating the efficiency of a Large Language Model (LLM), it’s crucial to consider three key categories: the model’s inherent processing capabilities, API performance, and hardware requirements.
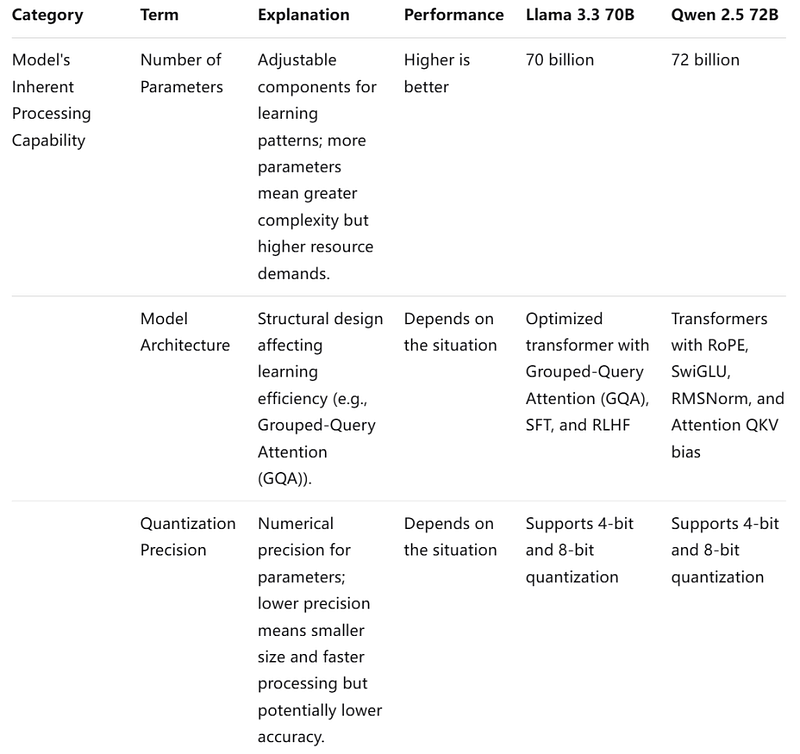
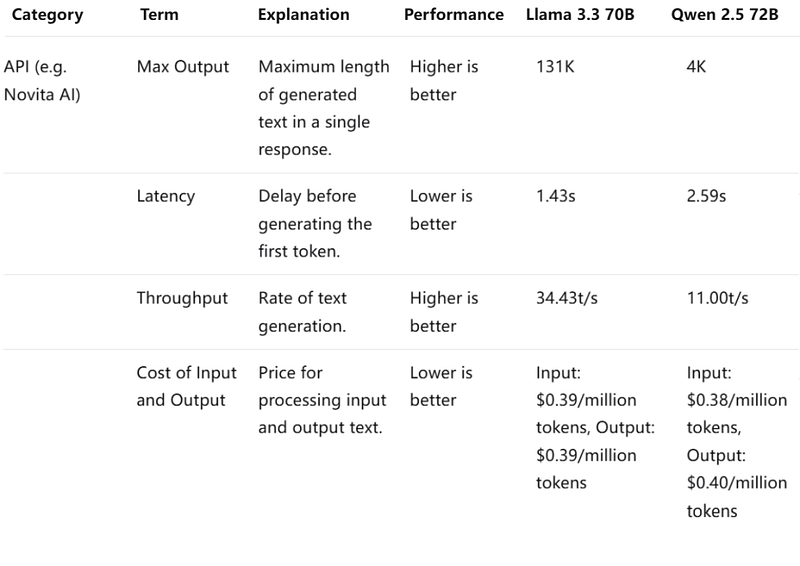
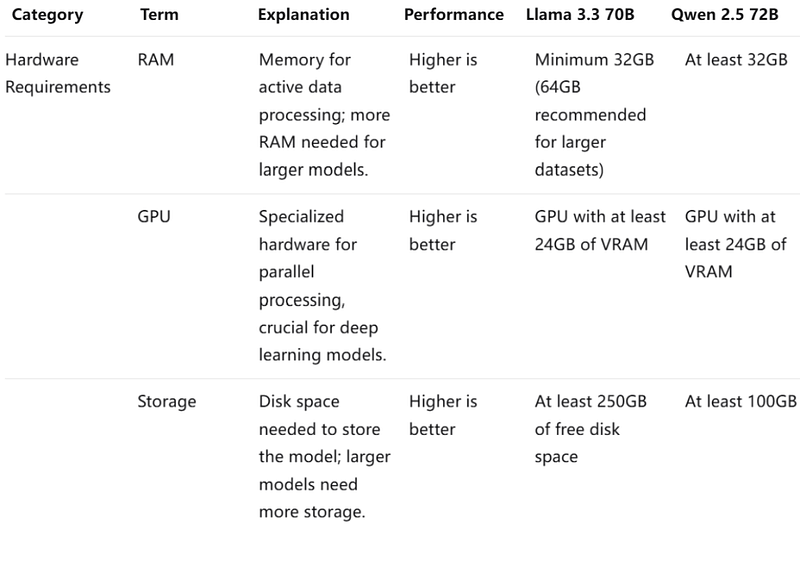
Llama 3.3 70B excels in API performance with higher max output, lower latency, and higher throughput, making it more efficient for quick and extensive text generation. It also provides clear guidelines for hardware requirements, suggesting better accessibility and scalability.If you want to use it, Novita AI provides a $0.5 credit to get you started !
Applications and Use Cases
To better understand how these models perform in real-world scenarios, let’s look at some application case studies.

We can find that Qwen 2.5 72b offers specialized models and broader language support, while Llama 3.3 70b shows strong performance in specific benchmarks and efficiency in deployment.
Accessibility and Deployment through Novita AI
Novita AI offers an affordable, reliable, and simple inference platform with scalable Llama 3.3 70b and Qwen 2.5 72b API*, empowering developers to build AI applications.*
Step1: Log in and Start Free Trail !
you can find LLM Playground page of Novita AI for a free trial! This is the test page we provide specifically for developers! Select the model from the list that you desired. Here you can choose the Llama 3.3 70b and Qwen 2.5 72b model.
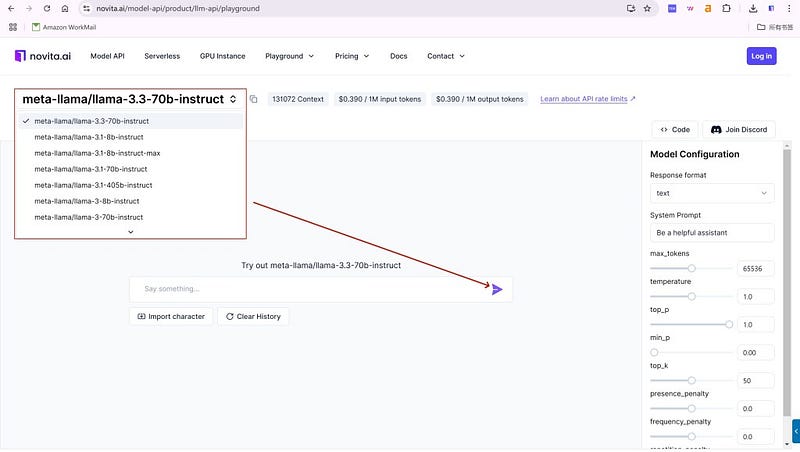
Step2: If the trial goes well, you can start calling the API!
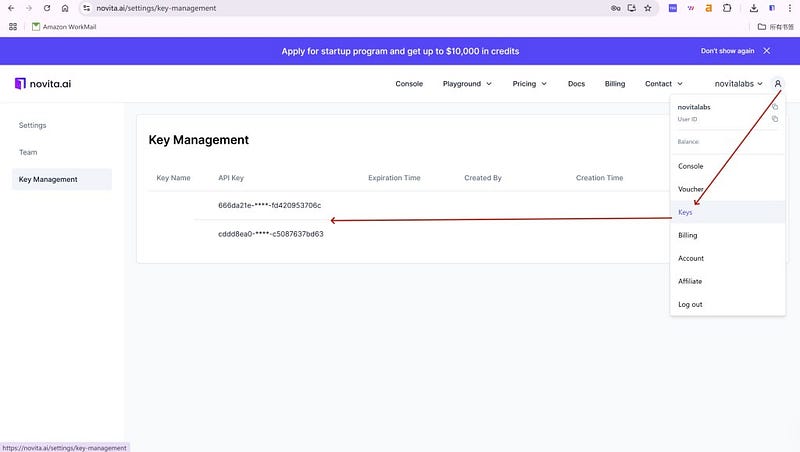
Click the “API Key” under the menu. To authenticate with the API, we will provide you with a new API key. Entering the “Keys“ page, you can copy the API key as indicated in the image.
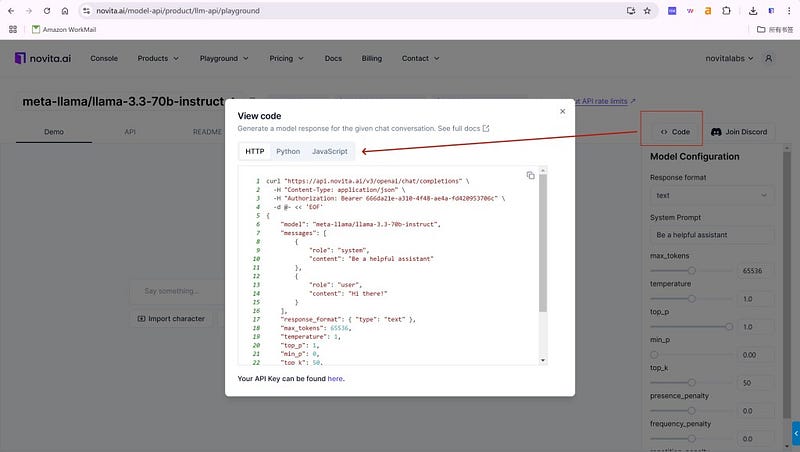
Navigate to API and find the “LLM” under the “Playground” tab. Install the Novita AI API using the package manager specific to your programming language.
Step3: Begin interacting with the model!
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
Conclusion
In conclusion, Qwen 2.5 72b and Llama 3.3 70b represent significant advancements in open-source LLMs, each with its own strengths. When choosing between these models, consider your specific project requirements, available resources, and the nature of the tasks at hand.
If you need a versatile model with strong multilingual support and specialized capabilities, Qwen 2.5 72b might be the better choice.
On the other hand, if your priorities are efficient local deployment, lower costs, and excellent instruction following, Llama 3.3 70b could be the ideal option.
Ultimately, both models offer impressive capabilities that can significantly enhance various natural language processing applications.
As the field of AI continues to evolve, these open-source models bring advanced AI capabilities within reach of a broader range of developers and organizations, paving the way for innovative applications and further advancements in the field.
Frequently Asked Questions
Is Qwen 2.5 any good?
Qwen 2.5 is a game-changer. Got my second-hand 2x 3090s a day before Qwen 2.5 arrived. I’ve tried many models. It was good, but I love Claude because it gives me better answers than ChatGPT. I never got anything close to that with Ollama.
What is llama 3 good for?
Chatbots: Since Llama 3 has a deep language understanding, you can use it to automate customer service.
Content creation: By using Llama 3, you can generate different types of content, varying from articles and reports to blogs and even stories.
originally from Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.