Revolutionizing Large Language Model Inference: Speculative Decoding and Low-Precision Quantization


With the rapid advancement of artificial intelligence(AI), large language models (LLMs) have emerged as a cornerstone of natural language processing (NLP). These models demonstrate remarkable capabilities in language generation and understanding, making them integral to applications such as machine translation, conversational systems, and text generation. However, as the size of these models continues to grow, their inference efficiency and resource consumption remain significant bottlenecks for large-scale deployment.
In recent years, researchers have proposed various optimization techniques to enhance the efficiency of LLM inference. In our previous work, we achieved a 1.5x speedup in inference by leveraging dynamic KV-cache compression based on the very large language model(vLLM) framework, laying a solid foundation for optimizing LLM performance.
This paper delves into two additional optimization strategies: speculative decoding and low-precision quantization. These approaches aim to maximize the computational capabilities of mainstream hardware, reduce inference costs, and improve speed. By employing these techniques, we seek to provide new perspectives and practical solutions for enhancing LLM inference efficiency, addressing the challenges of scalable AI deployment.
Speculative Decoding
Technical Principles
Speculative decoding is a technique that accelerates inference by introducing a smaller model to generate multiple candidate tokens, which are then validated by the larger model, enabling parallel decoding to improve speed. The feasibility of this approach is based on two key factors:
Memory Bottleneck
In modern GPU hardware, memory access bandwidth is often slower than the computational speed required for inference, making the process significantly memory-bound. The GPU memory traffic during the inference stage of large language models is primarily determined by model size, while GPUs often have surplus computational capacity. By leveraging this surplus through parallel inference with a small model, overall efficiency can be improved.
Small Model Prediction Accuracy
Current mainstream language generation models are typically autoregressive models based on the Transformer architecture. Small models exhibit high accuracy in predicting common language patterns (e.g., idiom collocations or standard expressions). When the small model successfully predicts the next token, the large model can directly reuse this result, significantly reducing computational cost.
Implementation Method
The speculative decoding method mainly consists of the following steps:
Multi-Round Candidate Generation
Use a specially trained small model for fast inference, generating multiple high-quality candidate tokens for each position.
Innovatively adopt a dynamic probability threshold adjustment mechanism to adaptively control the number of candidates.
Introduce a context-aware caching mechanism to improve the small model's prediction accuracy during continuous text generation.
Efficient Verification Strategy
Design a batch verification mechanism to group multiple candidate tokens and send them into the large model for a single scoring process.
Implement an early termination strategy to quickly return results when a high-confidence match is found.
Enable asynchronous processing of verification results to reduce GPU idle waiting time.
Intelligent Scheduling System
Dynamically balance the allocation of computational resources between small model prediction and large model verification.
Use adaptive prediction based on historical statistics to optimize candidate token generation strategies.
Implement fine-grained task partitioning and scheduling to maximize hardware utilization.
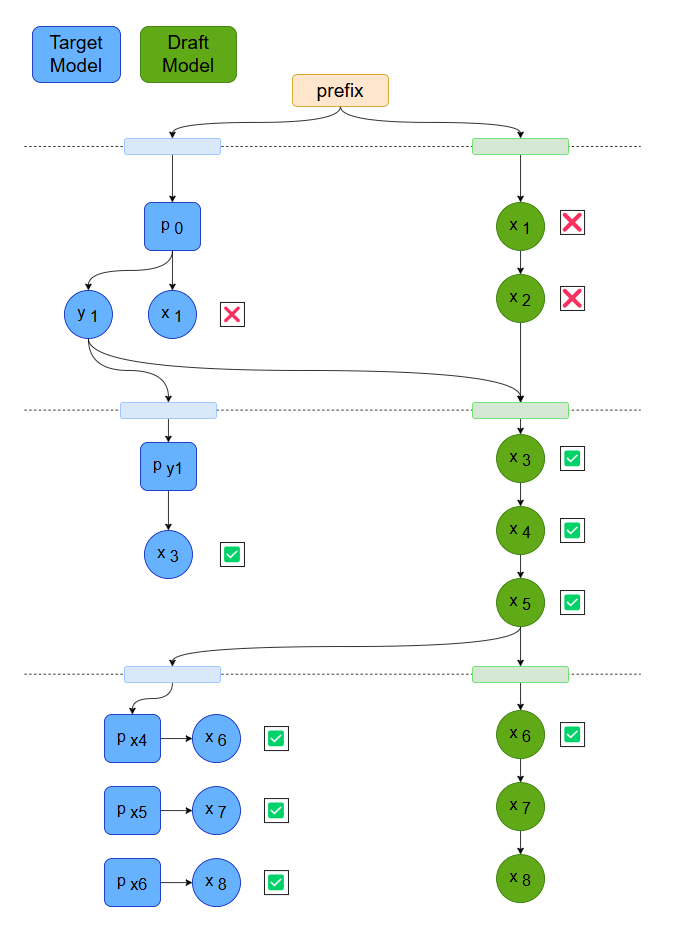
Fig.1. Speculative decoding with dynamic draft length
Experimental Results
Based on the industry-leading vLLM inference framework, we conducted deep customization and development, achieving significant performance improvements. We conducted experiments using the LLaMA-3.1-70B-Instruct model on an H20 GPU and tested scenarios with varying context lengths. Additionally, we compared the performance with vLLM without speculative decoding, focusing on throughput under different batch sizes, the experimental results are shown in Figure 2.
Performance Improvements
Achieved a 1.4x overall inference speedup while maintaining output quality.
Fully compatible with existing vLLM functionality and can be seamlessly integrated into current systems.
Supports language models of various scales, with particularly significant improvements for large-scale models.
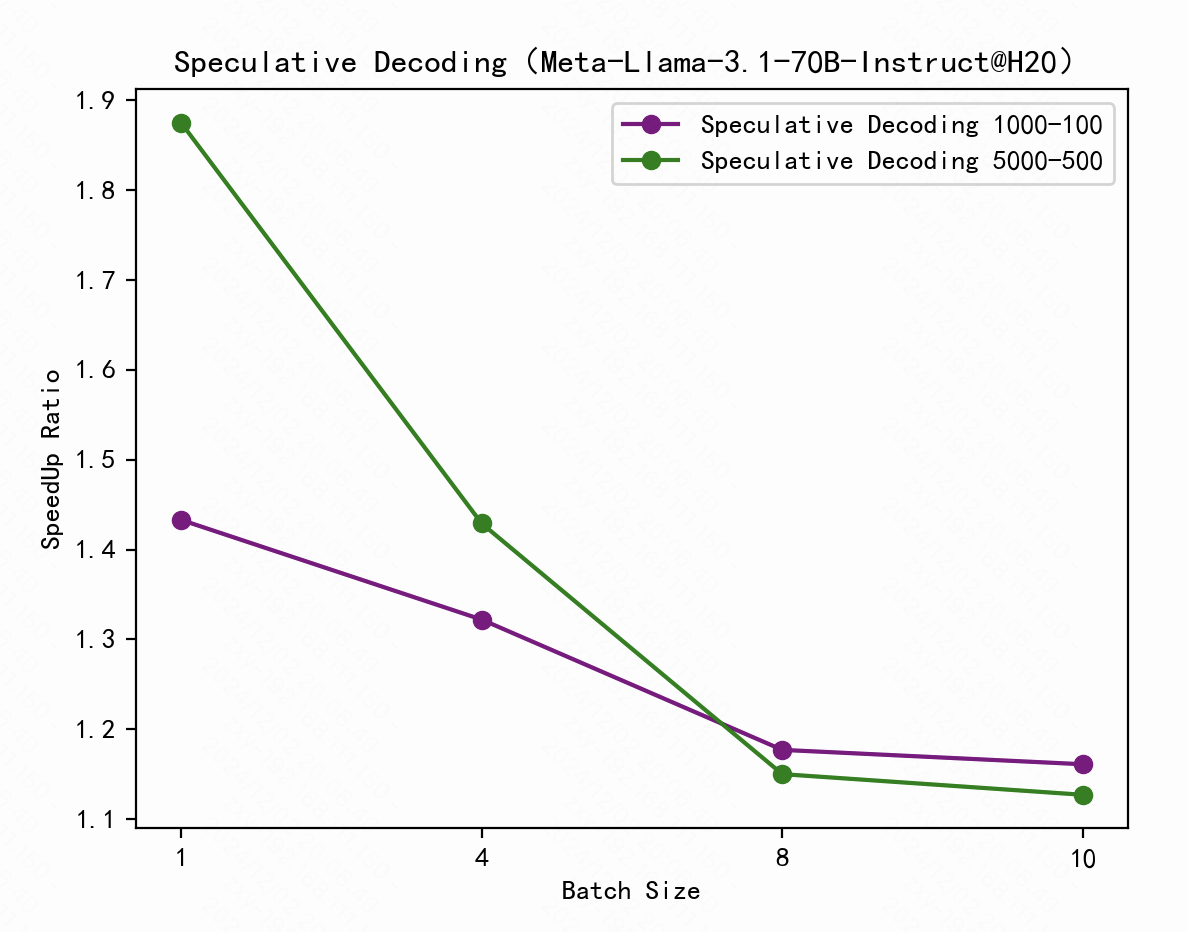
Fig.2. Speculative decoding speedup ratio diagram.
Technical Advantages
Probability-based dynamic sampling strategy for efficient token drafting and verification.
The stable intelligent scheduling mechanism ensures consistent acceleration effects.
Cost-effective with low resource overhead.
Low-Precision Quantization
Technical Principles
- Overview of Quantization
Quantization is a widely adopted technique that reduces the computation and memory costs of large-scale language models (LLMs) by converting the model weights and activations from high-bit-width representations to lower-bit-width representations. Specifically, many methods involve quantizing FP16 tensors into low-bit integer tensors, as shown below:
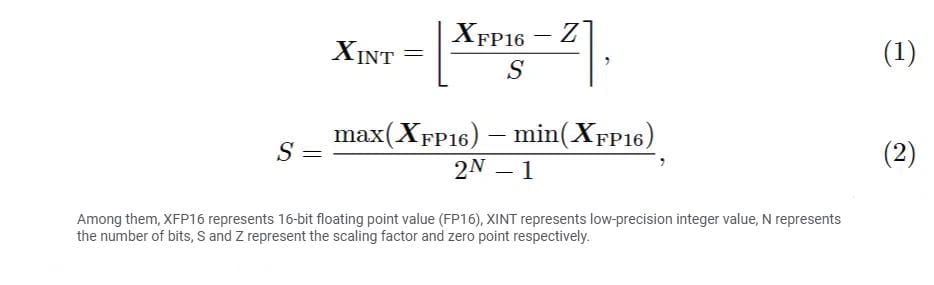
- Post-Training Quantization (PTQ)
PTQ quantizes pre-trained models without requiring retraining, thus avoiding high retraining costs. However, applying traditional quantization methods to LLMs introduces unique challenges:
LLMs exhibit a higher frequency of outliers in weights and activations, as well as broader distribution ranges, compared to smaller models.
- Therefore, effective quantization of LLMs demands specialized optimization techniques to minimize precision loss while maintaining efficiency.
Implementation Method
- Outlier Optimization
The presence of outliers in the weights and activations of large language models presents a significant challenge during the quantization process. Traditional methods typically handle outliers through clipping or simple scaling, which may work well for smaller models but often significantly affect the performance of LLMs.
Our approach improves the outlier handling process through detailed analysis and optimization strategies. It not only refines the computation of outliers but also optimizes the associated data structures, ensuring that the model retains efficient computational power while minimizing precision loss. For example, we adopt a more flexible dynamic range distribution strategy to process outliers hierarchically, capturing the model's characteristics more accurately.
- Improved Operators and Layer Fusion
We designed a series of improved operators that can more efficiently process quantized data structures. For example, through layer fusion techniques, we combine multiple consecutive operators into a single operator during forward computation to reduce computational overhead and intermediate data transfer.
Additionally, for common operations such as matrix multiplication combined with activation functions, we designed efficient low-bit operators to accelerate model inference. This improvement not only significantly reduces the bandwidth demands at the hardware level but also further enhances overall computational efficiency.
- Unique FP8 Quantization Scheme
While mainstream quantization methods in the industry generally use conversion from FP16 to INT8, this approach may not be suitable for scenarios requiring lower precision. Our FP8 quantization scheme introduces an adaptive scaling factor to further reduce bit width while retaining the model's numerical expressiveness. In the implementation, we adjust the ratio of the exponent and mantissa in FP8 to better adapt to the distribution characteristics of LLMs, ensuring that the model maintains accuracy even with very low bit widths.
- KVCache Quantization
In scenarios supporting large-scale inference, the storage and access efficiency of KVCache are crucial. Traditional methods often apply standard quantization techniques without optimizing for the specific characteristics of KVCache storage structures.
We propose a specialized KVCache quantization technique that minimizes computational resource requirements by applying specific quantization strategies to queries and key-value pairs. Specifically, we optimize the dynamic updates and storage density of KVCache, combining piecewise quantization and sparse matrix storage methods to significantly improve cache utilization during the inference process.
- Inference Process Optimization
Model weights in FP16 are quantized into FP8 format for inference. Input tokens pass through the embedding layer and the Transformer module, including attention mechanisms and feed-forward networks.
Using FP8 TensorCore and optimized KVCache, the system efficiently stores and updates key-value pairs.
Linear transformations and the Softmax layer generate the output probability distribution, producing the final token output.
This approach leverages FP8 TensorCore's computational efficiency to deliver faster inference at lower computational costs. In Figure 3, model weights, originally in FP16 format, are quantized to FP8 for inference, significantly reducing data access overhead and improving speed. During the LLM inference process, operations such as QKV projection, flash attention, and feedforward layers undergo matrix multiplication in FP8 format. These computations are accelerated using Tensor Cores, leading to a substantial increase in inference speed. To mitigate precision loss, a small amount of additional data is used for PTQ, ensuring that the model's inference accuracy remains intact. In long-text scenarios, the overhead associated with KV data access can slow down inference speed. To address this, the KV data is also quantized to FP8, further optimizing the model’s inference performance.
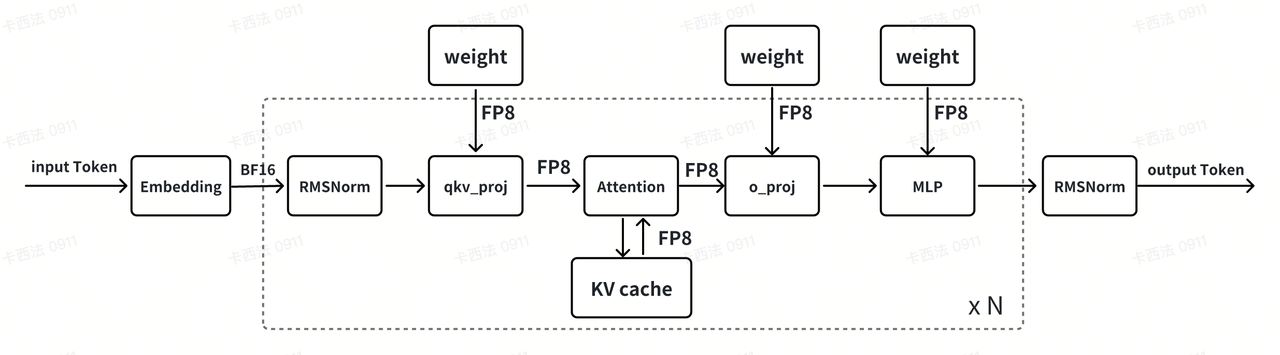
Fig.3. An overview of the FP8 precision quantization pipeline.
Experimental Results
- Figure 4 shows the speedup ratio after applying low-precision quantization to Llama3-8B-BF16, with different input-output lengths (10000-1000, 5000-500, 2000-200) and batch sizes (Batch Size). The longer the input-output length, the more significant the speedup effect, especially during large batch inference. On a single 4090 GPU running Llama3-8B-FP8-KV8, with ttft (time-to-first-token) limited to under 2 seconds, the batch size is around 4, and the speedup ratio is 1.4x.
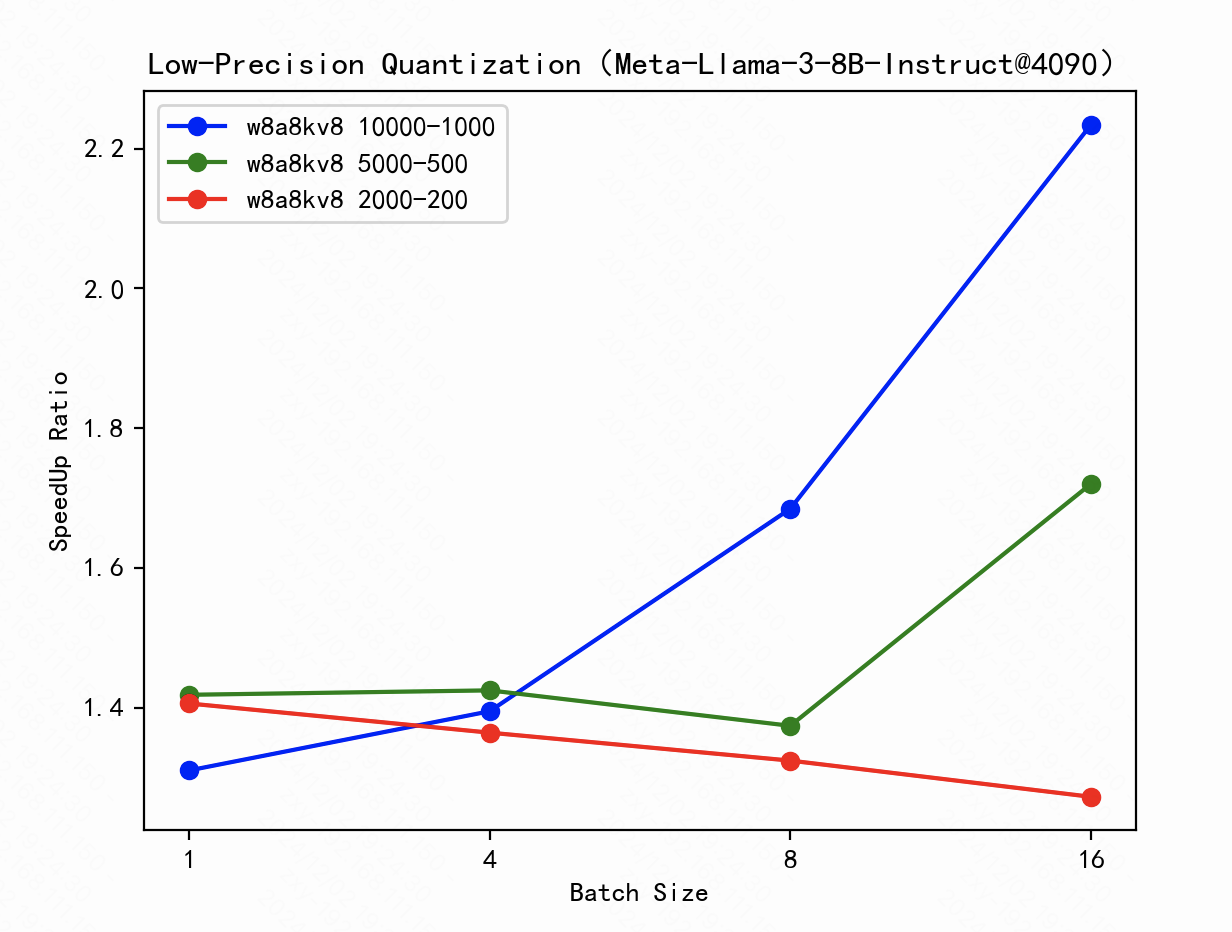
Fig.4. Speedup ratio by FP8 quantization.
Our method significantly reduces the impact of outliers when handling larger input-output lengths and enhances computational and transfer efficiency through optimizations such as layer fusion. Traditional industry PTQ methods often struggle with handling large input-output lengths in large-scale models, but our solution is specifically designed to address this issue, ensuring stable model performance.
Experiments show that on a 4090 GPU, our method demonstrates superior speedup when processing large-length input-output and medium batch sizes, while maintaining an inference latency (ttft) below 2 seconds, meeting real-time inference requirements.
Quality Evaluation
To test different model APIs (such as openrouter.ai) on the mmlu_pro (5-shot) test set using the lm-evaluation-harness tool, follow these steps for inference with the tool's default configuration. The results are shown in Figure 5.
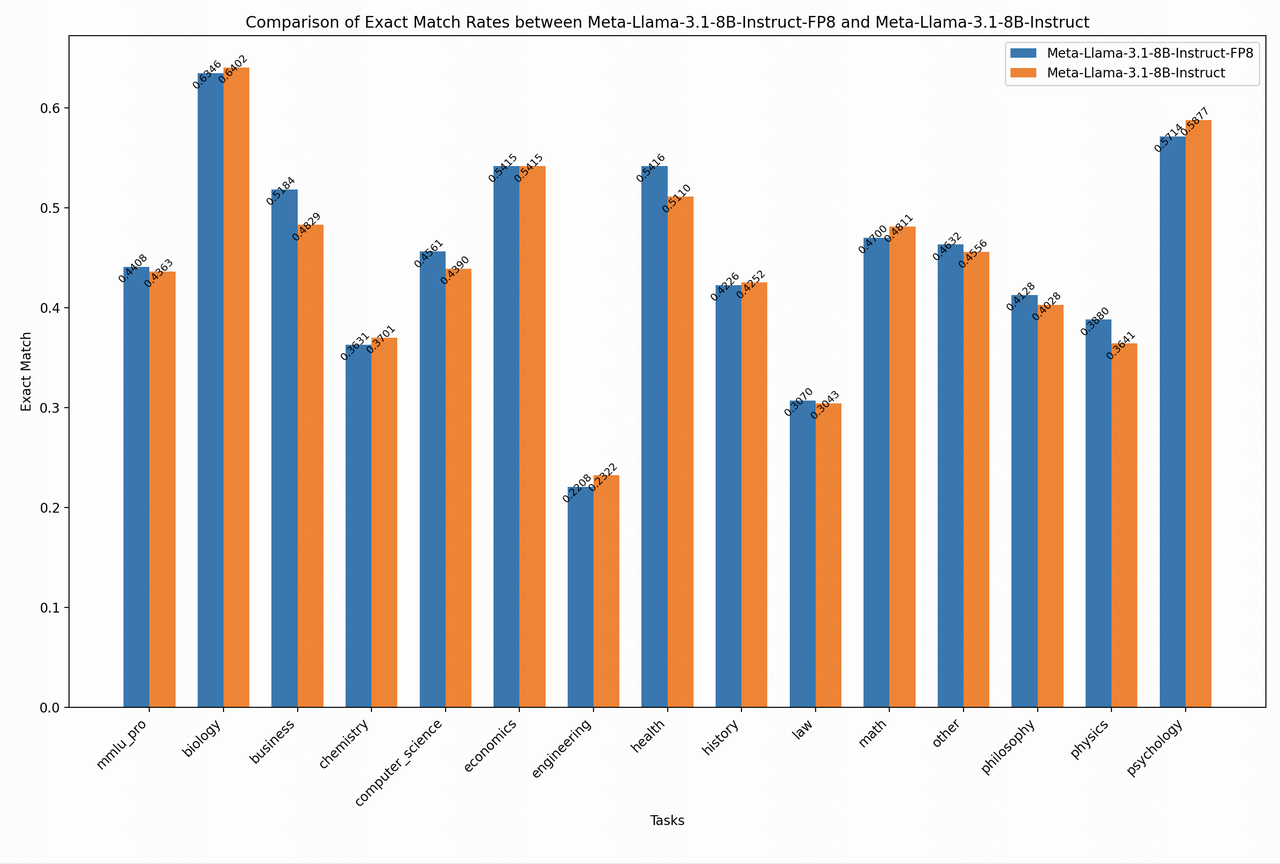
Fig.5. Comparision of exact match rates between Meta-Liama-3.1-8B-Instruct-FP8 and Meta-Liama-3.1-8B-Instruct.
Conclusion
This paper presents speculative decoding and low-precision quantization as complementary techniques aimed at enhancing the efficiency of large language model (LLM) inference. Speculative decoding accelerates the inference process by leveraging a smaller model to generate candidate tokens, which are subsequently validated by the larger model in parallel, yielding a 1.4x speedup.
In contrast, low-precision quantization mitigates computational and memory overheads by transforming model weights into lower bit-width representations, all while maintaining model performance. Collectively, these methodologies provide novel insights and practical solutions for achieving high-efficiency inference, complementing existing techniques such as dynamic KV-cache compression.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading