


Key Highlights
LLaMA 3.3 70B ’s 70 billion parameters require significant VRAM, even with quantization.
GPUs like the NVIDIA RTX 3090 or 4090 are recommended for running the model effectively.
Home servers might face limitations in terms of VRAM, storage, power, and cooling.
Optimization techniques and careful configuration are crucial to run LLaMA 3.3 70B locally.
Independent developers can cut costs by using an API service,such as Novita AI.
LLaMA 3.3 70B is a strong language model with benchmark challenges for people who run servers at home because it needs a lot of VRAM. Even though running large language models on your own computer can give you privacy and ways to customize, it can be too much for average home server setups. This blog post will look into how much VRAM LLaMA 3.3 70B needs and talk about the tech problems it creates for home servers.
Exploring LLaMA 3.3 70B VRAM Requirements

LLaMA 3.3 70B is a powerful, large-scale language model with 70 billion parameters, designed for advanced natural language processing tasks, offering impressive performance for complex AI applications.
Detailed Hardware Requirements
To run LLaMA 3.3 70B, you need good hardware that works well together. The GPU, CPU, and RAM should all support each other to give you the power and memory you need. Firstly ,we should know the meaning of various hardware requirements.
Component Requirement CPU Minimum 8-core RAM Minimum 32 GB; Recommended 64 GB+ VRAM ~35 GB (4-bit quantization); up to 141 GB (higher precision) GPU NVIDIA RTX series; A100 Storage ~200 GB

Comparing VRAM Requirements with Previous Models
Llama 3.3 70B represents a significant advancement in AI model efficiency, as it achieves performance comparable to previous models with hundreds of billions of parameters while drastically reducing GPU memory requirements. Specifically, Llama 3.3, a model from Meta, can operate with as little as 35 GB of VRAM requirements when using quantization techniques, compared to the 148 GB required by the larger model Llama 3.1–70B or 140GB required by Llama 2 70B. This optimization allows users to potentially save up in initial GPU costs.

However, despite these improvements, the overall deployment costs remain relatively high due to the need for advanced hardware, ongoing electricity expenses, and specialized personnel for maintenance and optimization.
How to Select a GPU That Meets llama 3.3 70B VRAM Requirements
Make sure the GPU has enough VRAM to meet the model’s needs. Choose GPUs that can manage the heavy tasks while staying stable.
Factors Affecting GPU with LLaMA 3.3 70B
VRAM Capacity:A higher VRAM (at least 24GB) is crucial for running large models like LLaMA 3.3 70B without memory limitations. More VRAM ensures smoother performance during model loading and inference tasks.
Computational Power (TFLOPs):TFLOPs measure GPU speed in handling complex calculations. A GPU with higher TFLOPs can accelerate text generation and deep learning tasks, leading to faster results.
Cost and Compatibility:Balance the GPU’s performance with your budget. Also, check compatibility with your existing hardware and software frameworks to ensure smooth integration into your setup.
Recommended GPUs for Running LLaMA 3.3 70B
When choosing a suitable GPU and considering various variants, consider your budget and desired performance level.
Here’s a breakdown of recommended GPUs for different needs:

For Small Developers, Renting GPUs in the Cloud Can Be More Cost-Effective
When buying a GPU, the price may be higher. However, renting GPU in GPU Cloud can reduce your costs greatly for it charging based on demand.Just like NVIDIA RTX 4090, it costs $0.35/hr in Novita AI, which is charged according to the time you use it, saving a lot when you don’t need it.
Here is a table for you:

Technical Challenges for Home Servers

Running LLaMA 3.3 70B on a home server using Python can be tough. Most home servers do not have enough resources for this large language model. You may first run into problems with VRAM. After that, storage, power, and cooling issues can also come up.
Insufficient VRAM and Storage:One of the biggest challenges in running Llama 3.3 70B is the need for substantial VRAM — approximately 35 GB — and ample storage space. High-end GPUs like the NVIDIA RTX 3090 or A100 are often required, making it difficult for users with standard hardware to meet these demands.
Power and Cooling Requirements:High-performance GPUs consume a significant amount of power, often exceeding 600 watts in dual setups, which can strain home electrical systems. Additionally, these GPUs generate considerable heat, necessitating effective cooling solutions to prevent overheating, adding complexity to the setup.
Network Bandwidth and Latency:Running Llama 3.3 effectively requires high network bandwidth and low latency. Insufficient bandwidth can lead to slow data transmission and increased latency, severely impacting performance, especially in multi-user scenarios where real-time responses are critical.
Scalability and Multi-GPU Setup:Scalability poses a significant challenge when deploying Llama 3.3. While it can run on a single GPU, utilizing multiple GPUs is necessary for optimal performance. However, setting up a multi-GPU environment is complex and requires compatible hardware, making it difficult for many users to achieve the desired performance levels.
So, what are the ways to optimize home servers?
Optimizing Home Servers for LLaMA 3.3 70B
1.Configuration Tips for Maximum Efficiency
Make sure to keep your operating system, drivers, and AI frameworks up to date. This helps to gain the latest performance upgrades and fix bugs. You might also want to look into undervolting your GPU. This means lowering the voltage to the GPU a little bit. It can help cut down power use and heat without lowering performance much.
Think about using Docker containers to make a separate and easy-to-manage space for running LLaMA 3.3 70B. This can help manage dependencies and avoid software issues, making your setup simpler to handle.
2.Memory Management
Even if you have a powerful GPU, good memory management is very important when using a model like LLaMA 3.3 70B. It is key to allocate memory well and use optimization techniques. One method to try is gradient checkpointing. This technique is often used during training but can also help during inference to lower memory use. This saves memory even if it takes a bit longer to compute.
Also, look at using transformer model pruning and quantization. Pruning means taking out less important connections in the model. This can make the model smaller and use less memory while usually keeping its performance.
But for small developers, how can they further reduce costs while ensuring model effectiveness?
For Small Developers, Using API to access llama 3.3 70B Can Be More Cost-Effective
When you have tried all optimization methods and your AI application still needs too much cost, it’s time to look for a more budget-friendly API option.
How API Access Reduces Hardware Costs for LLaMA 3.3 70B
API access to LLaMA 3.3 70B allows organizations to use the model without heavy investments in high-end hardware, as they can leverage cloud services like Novita and pay only for the computational resources they consume. This significantly reduces upfront costs.
Additionally, API services often feature automatic scaling, which adjusts resources based on demand, preventing over-provisioning and optimizing resource allocation. Novita’s infrastructure can quickly scale to meet demand while handling model updates and data scaling efficiently offline, ensuring continuous performance without delays.
Novita AI: the Most Suitable Option.
Novita AI offers an affordable, reliable, and simple inference platform with scalable Llama 3 .3 70B API, empowering developers to build AI applications on Facebook. With a commitment to transparency and affordability, It provides the most competitive rates in the industry — starting as low as $0.39 per million tokens.
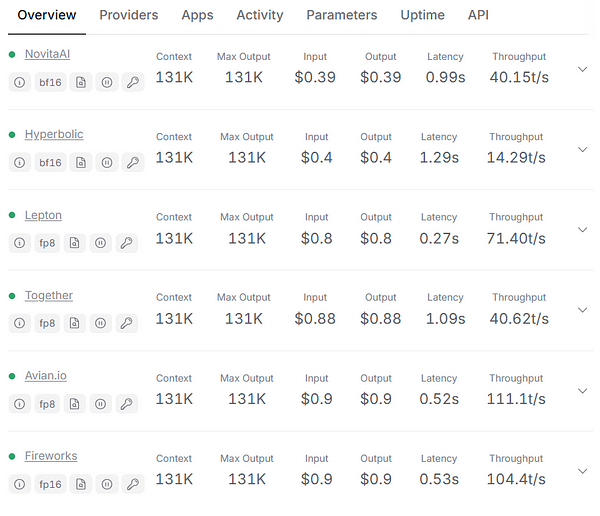
Next, I will give you a detailed introduction on how to use llama 3.3 70B api on Novita AI.
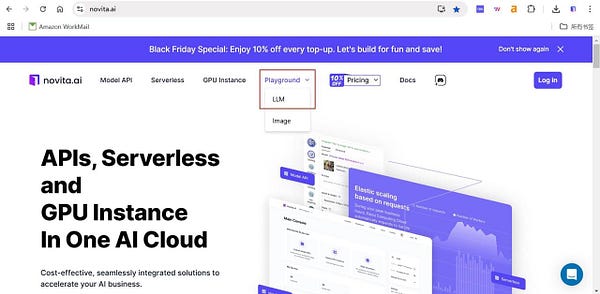
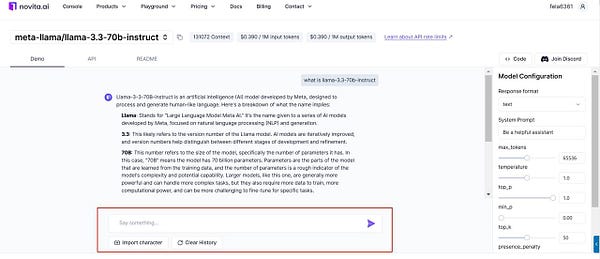
Step1: you can find LLM Playground page of Novita AI for a free trial! This is the test page we provide specifically for developers!
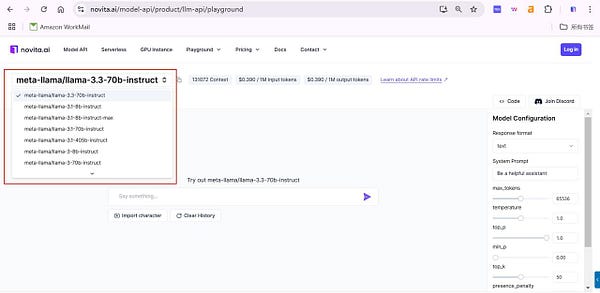
Step2: Select the model from the list that you desired. Here you can choose the Llama-3.3–70b-instruct machine learning model for your use case.
Step3: Set the parameters according to your needs like temperature, and max tokens.If you have any questions about the specific content of these parameters, you can click on the Docs above to view the specific meaning
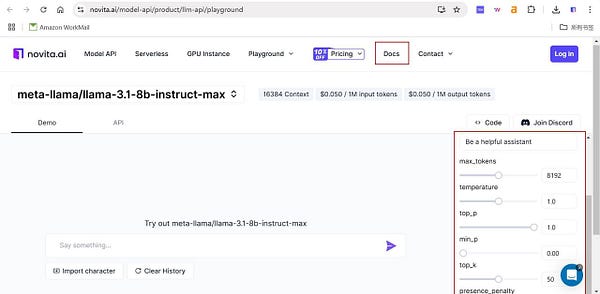
Step4: Click the button on the right, then you can get content in a few seconds.Try it today!
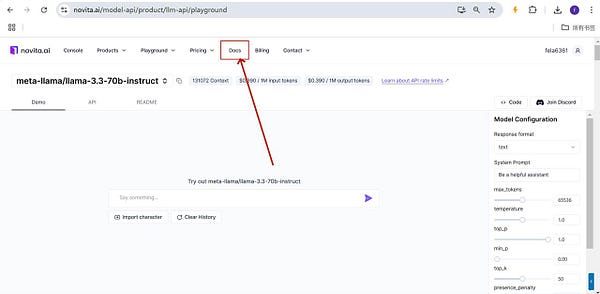
Step5: If you think the test results meet your needs, you can go to the Docs page to make an API call!
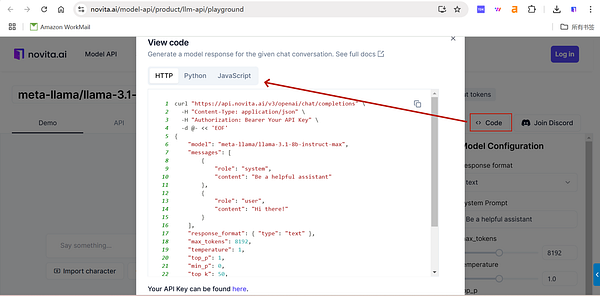
Fortunately, Novita AI provides free credits to every new user, just log in to get it! Upon registration, Novita AI provides a $0.5 credit to get you started! If the free credits is used up, you can pay to continue using it.
Conclusion
In conclusion, deploying LLaMA 3.3 70B at home is challenging due to its high VRAM requirements, around 35 GB, which necessitates expensive hardware that may not be feasible for independent developers.However, API access offers a practical solution. By using cloud services, like Novita AI developers can utilize LLaMA 3.3 70B without investing in costly infrastructure, paying only for the resources they consume.
Frequently Asked Questions
1.What is the minimum VRAM requirement for running LLaMA 3.3 70B?
For LLaMA 3.3 70B, it is best to have at least 24GB of VRAM in your GPU. This helps you load the model’s parameters and do inference tasks well.
2.How can I optimize my existing home server to meet LLaMA 3.3 70B’s demands?
To make your home server better, focus on upgrading your GPU. This will give you enough VRAM. You can also try methods like quantization. This helps to lower the model’s memory use and can boost performance in your current setup.
Originally published at Novita AI
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.
Recommend Reading
1.How Much RAM Memory Does Llama 3.1 70B Use?