




Introduction
Are emergent abilities of large language models a mirage? The short answer to this question is: mostly, yes. Some scholars from Stanford argue that it’s all about metrics. To be specific, LLMs develop their abilities gradually, not abruptly according to most metrics, while these emergent miracles only show up in certain metrics. In this blog, we explore the original definition of emergent abilities of large language models, how these scholars challenge the claim and implications of their findings in the AI world.
What Are Emergent Abilities of Large Language Models?
Emergent abilities refer to new capabilities or behaviors that arise in complex systems as they scale up in size or complexity. In the context of LLMs, these are unexpected skills or improvements in performance that supposedly weren’t present in smaller models but appear as the model grows.
Characteristic 1: Sharpness
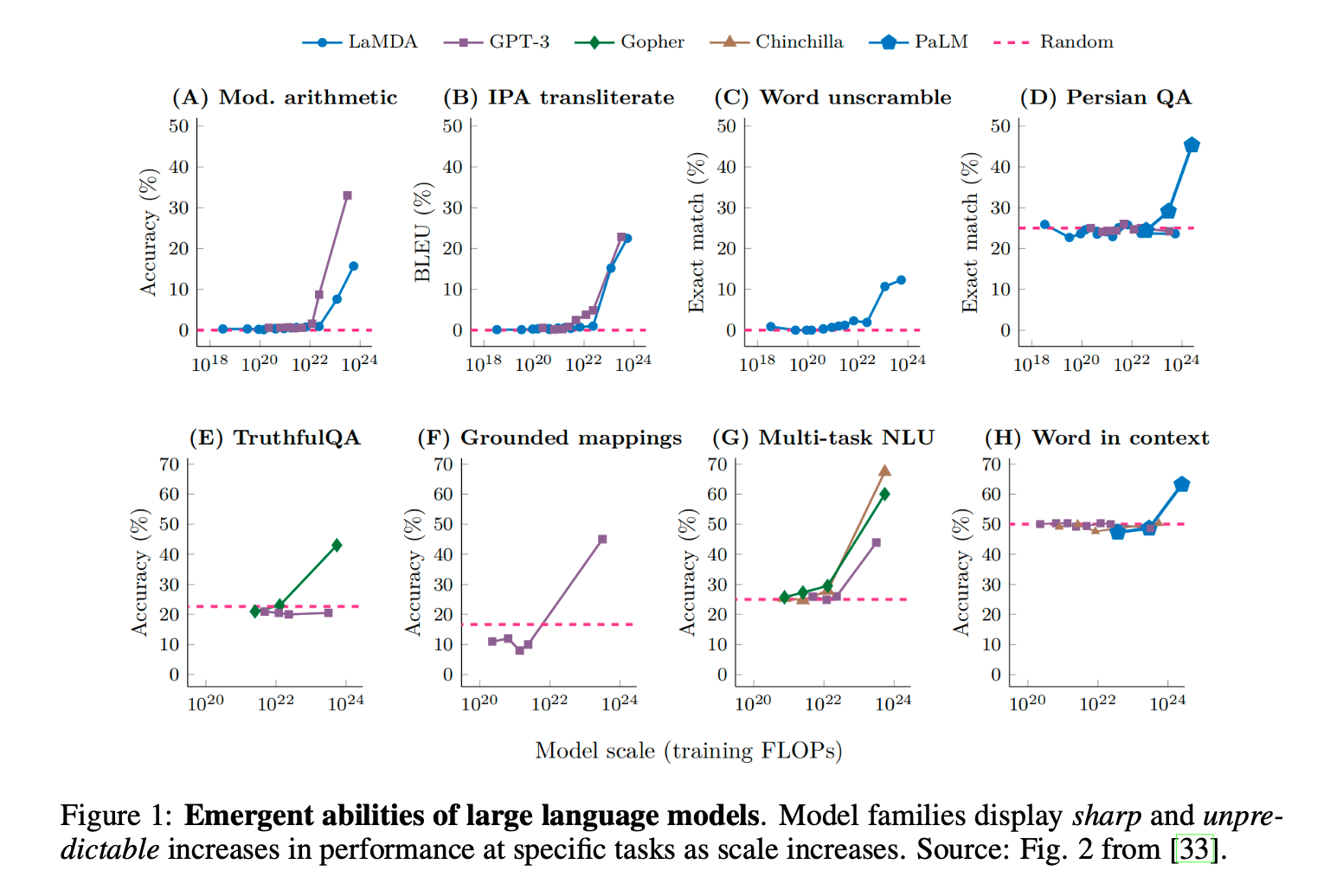
Sharpness in the context of emergent abilities refers to the sudden and dramatic increase in performance on a specific task. It’s as if the model has a “lightbulb moment” where it transitions from not being able to perform a task at all to doing it flawlessly. This is often visualized as a steep curve on a graph, showing performance metrics like accuracy or task completion rate jumping from a low value to a high one without much in-between.
Imagine you have a series of language models with varying sizes, from small to very large. You test their ability to translate text from English to French. The smaller models might struggle, providing poor translations with many errors. However, as you test larger and larger models, you might suddenly find that at a certain size, the model’s translations are almost perfect, with very few, if any, errors. This sudden improvement is what is referred to as the “sharpness” of the emergent ability.
Characteristic 2: Unpredictability
Unpredictability is about the difficulty in foreseeing when or at what size a model will exhibit an emergent ability. There isn’t a clear, gradual trend that you can point to and say, “When we reach this size or complexity, the model will be able to do X.” Instead, the appearance of these abilities seems to come out of the blue, without any obvious pattern or warning.
Continuing with the translation example, you might expect that as you increase the size of the model, its translation ability will steadily improve. However, unpredictability means that you can’t reliably predict at which exact model size the translations will become excellent. One model might show a leap in ability when it has 100 million parameters, while another might not show the same leap until it has a billion parameters. There’s no clear rule that tells you when this will happen, making the emergence of the ability unpredictable.
Challenging the Emergence Claim: Just A Mirage
The article titled “Are Emergent Abilities of Large Language Models a Mirage?” by Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo from Stanford University’s Computer Science department, challenges the notion that LLMs exhibit emergent abilities. As always, if you are not interested in the research details, just grab this takeaway and move to the next section: perceived “emergent abilities” in large language models may actually be an illusion created by the choice of performance metrics rather than a genuine and abrupt change in the models’ capabilities as they scale up in size.
Research Background & Research Question
The article begins by discussing the concept of emergent properties in complex systems, which has gained attention in machine learning due to observations of large language models (LLMs) displaying abilities not seen in smaller models. These emergent abilities are characterized by their sharpness and unpredictability.
The research question posed by the article is whether these emergent abilities are a fundamental property of scaling AI models or an artifact of the metrics used to measure performance.
Experiment Design
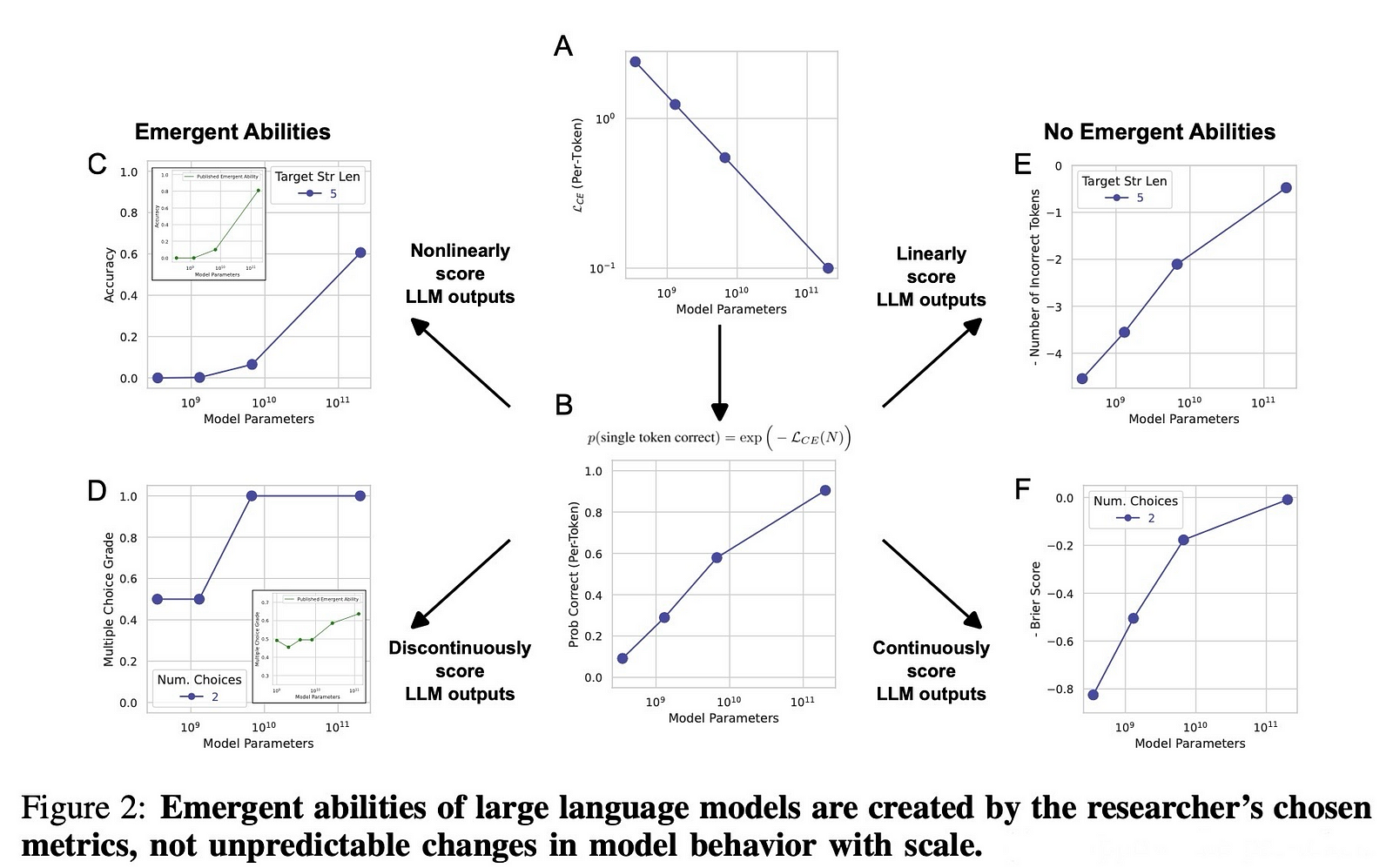
The authors propose an alternative explanation for emergent abilities, suggesting that they may be a result of the choice of metric rather than intrinsic model behavior. They present a mathematical model to demonstrate this and test their hypothesis through three complementary approaches:
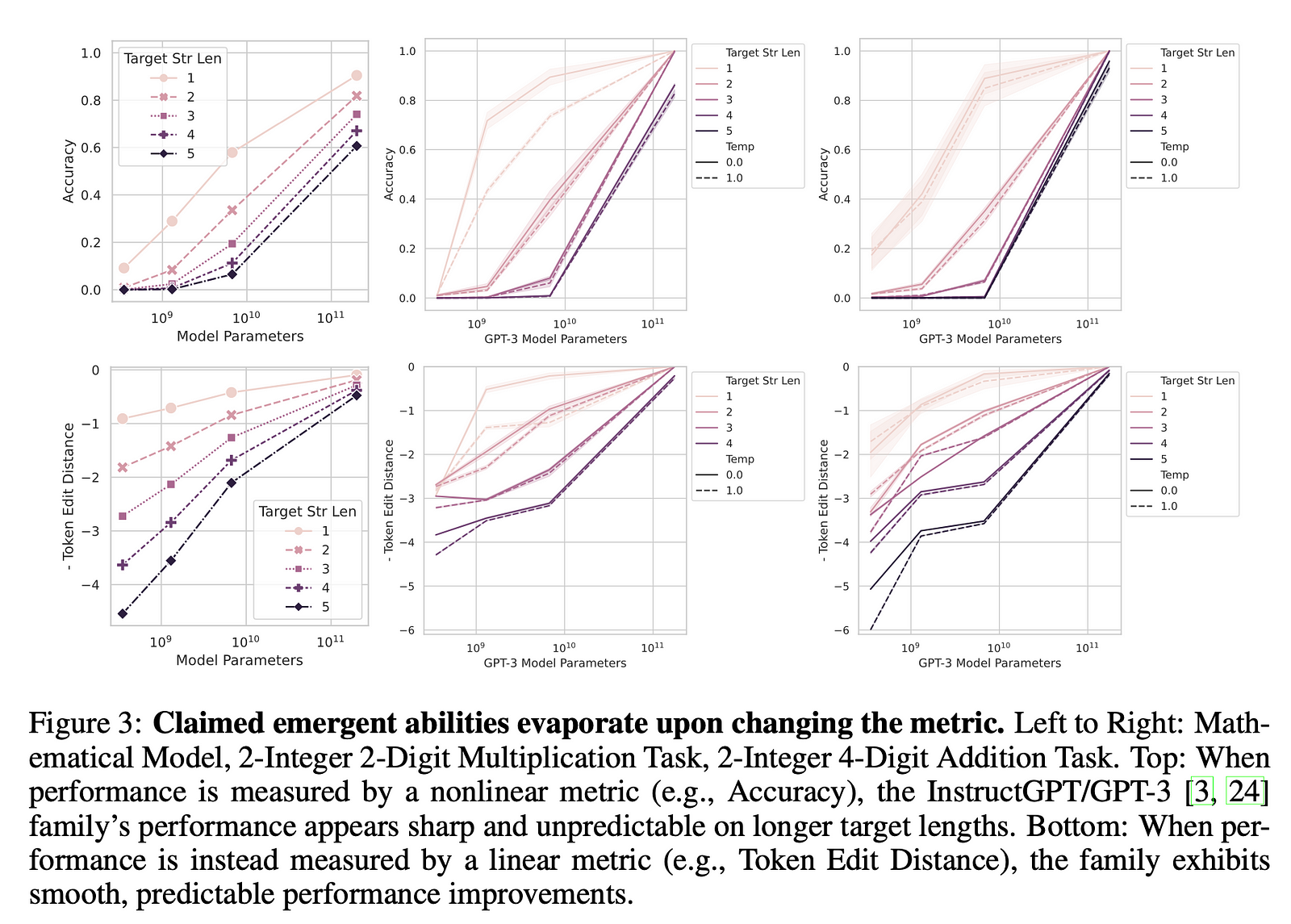
They tested their idea using a well-known AI model family (InstructGPT/GPT-3) on tasks where people said these special skills showed up. They looked at how changing the test scores (metrics) changed what we see.
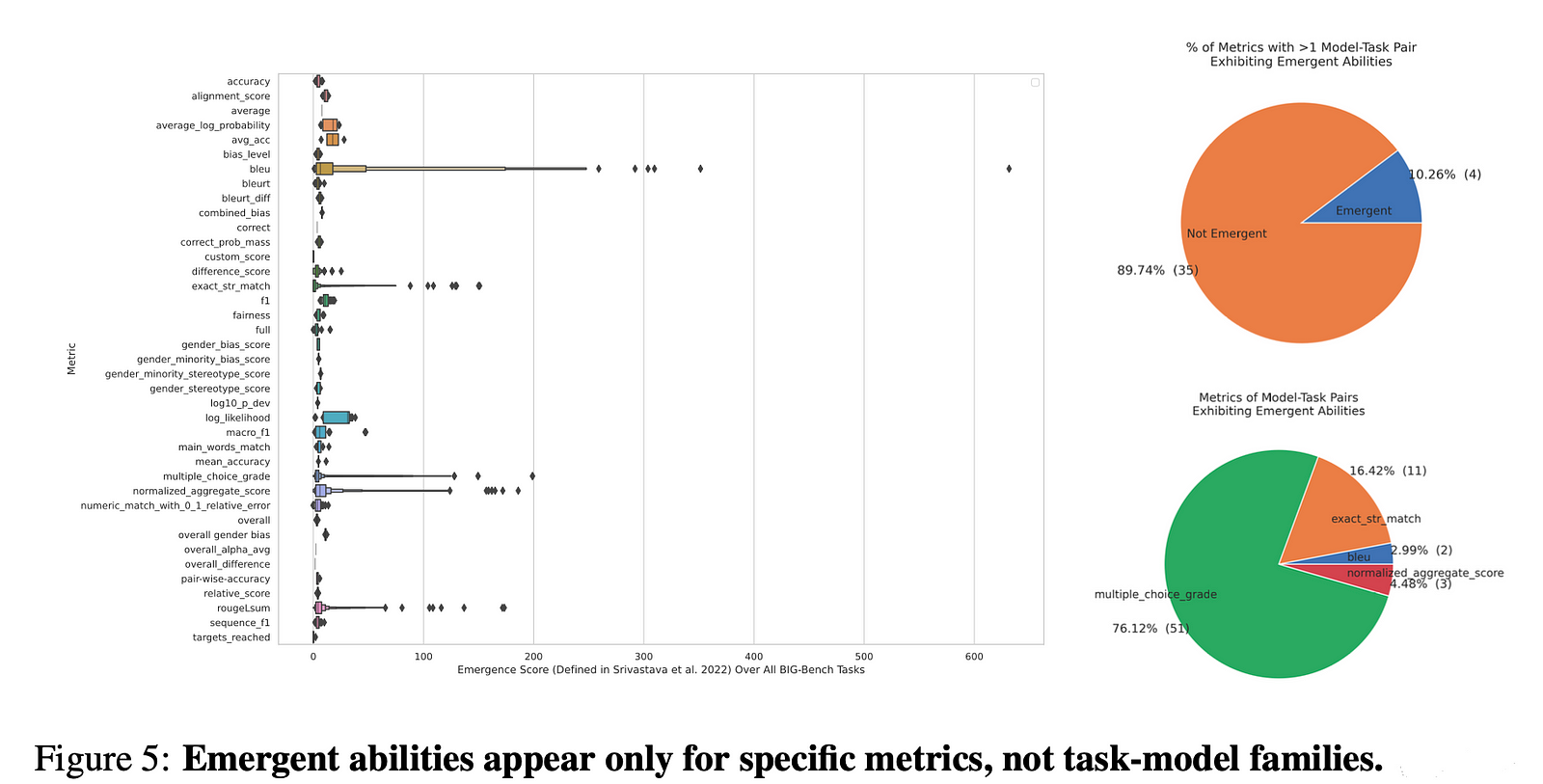
They conducted a meta-analysis of emergent abilities on a bunch of tests (BIG-Bench) to see if these special skills only showed up when using certain ways of scoring (metrics).
They induced seemingly emergent abilities in multiple vision tasks across diverse deep networks by changing evaluation metrics.
Findings
- The Test Results: When the researchers changed the way they measured the AI’s performance (the metrics), they saw something interesting. Instead of a sudden jump in the AI’s abilities, they found a smooth and steady improvement as the AI models got bigger. This was the opposite of what they expected if the AI really had “special skills” that appeared out of nowhere.

- Different Metrics, Different Stories: They found that certain ways of measuring performance made it look like the AI got a lot better really fast. But when they used different metrics that graded the AI more fairly, the improvements were more gradual. It was like the AI wasn’t suddenly getting smarter; it was just being tested in a way that made it look that way.
The Big Test (Meta-Analysis): When they looked at a bunch of different tests (the BIG-Bench), they saw that these “special skills” only showed up when certain metrics were used. It was like these skills were hiding and only appeared when the test was set up in a certain way.
Making Skills Appear: Finally, the researchers showed that they could make these “special skills” appear in other types of AI tasks (like recognizing pictures) just by changing how they measured the AI’s performance. It was like magic, but instead of a real magic trick, it was about how they were looking at the AI’s abilities.

Implications for AI Research and Development
Metric Selection
Researchers should carefully consider the choice of metrics when evaluating AI models. The paper suggests that nonlinear or discontinuous metrics might create a misleading perception of model capabilities. Choosing appropriate metrics that accurately reflect gradual improvements is crucial for valid and reliable assessment.
Benchmark Design
The design of benchmarks should take into account the potential influence of metric choice on the perceived abilities of AI models. Benchmarks should use a variety of metrics to provide a comprehensive assessment and avoid overemphasizing results from metrics that might induce the appearance of emergent abilities.
Interpretation of Results
Researchers should be cautious when interpreting results that suggest emergent abilities. The paper encourages a more nuanced understanding of model performance, taking into account the possibility that observed ‘emergent’ behaviors might be artifacts of the measurement process.
Model Transparency and Reproducibility
The paper highlights the importance of making models and their outputs publicly available for independent verification. This transparency is essential for the scientific community to validate claims and reproduce results, ensuring the integrity of AI research.
AI Safety and Alignment
If emergent abilities are perceived to arise unpredictably, it could have implications for AI safety and alignment. However, if these abilities are a result of metric choice, it suggests that researchers have more control over the development of AI capabilities than previously thought, which could be leveraged to guide AI development towards beneficial outcomes.
Resource Allocation
Understanding that emergent abilities might be a mirage can inform resource allocation in AI development. Instead of focusing on scaling models to achieve unpredictable abilities, resources might be better spent on refining algorithms, datasets, and training processes to produce desired outcomes in a more predictable manner.
Ethical Considerations
The ethical implications of AI capabilities are closely tied to our understanding of what AI can and cannot do. If emergent abilities are less common or less abrupt than believed, this could affect how we approach ethical guidelines and regulations for AI development and deployment.
Public Communication
Communicating AI capabilities to the public accurately is important for managing expectations and addressing concerns about AI. The paper’s findings suggest that caution should be exercised to avoid overstating AI capabilities and to provide a clear and realistic picture of AI’s current and potential future abilities.
Research Prioritization
The findings might lead researchers to prioritize understanding the fundamental mechanisms behind AI performance improvements over searching for elusive emergent abilities. This could involve more focus on algorithmic improvements, data quality, and training techniques.
Get Hands-on Experience with LLM’s Capabilities
Although the authors deny LLM’s capabilities as emerging, they do not indicate that LLM’s capabilities are not solid. LLMs’ abilities to solve problems in real-life scenarios are unquestionable. If you are eager to get hands-on experience with LLM’s capabilities, Novita AI provides AI startups with LLM APIs to leverage the power of LLMs.
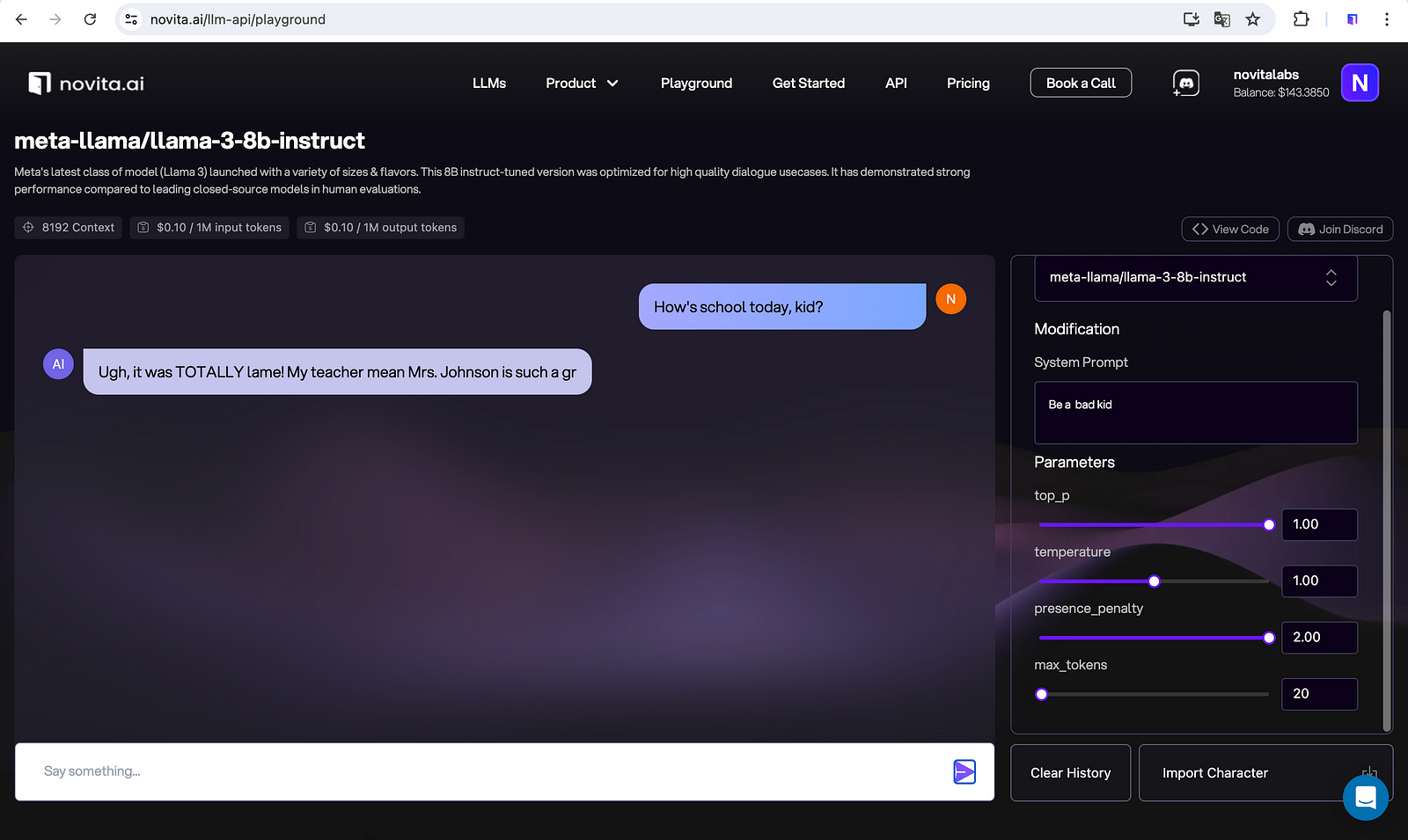
You can use our LLM free trial to compare performances of different LLMs which are integrated into our API later. Moreover, adjustments of parameters and system prompts are also allowed in the free chat to cater to your specific needs of LLM outputs.

Conclusion
The debate on whether large language models (LLMs) exhibit genuine emergent abilities or if these are a mirage, as suggested by researchers from Stanford, brings into focus the pivotal role of performance metrics in AI evaluation. The study posits that the sharp and unpredictable improvements attributed to LLMs may be an artifact of certain metrics rather than an intrinsic model capability.
This perspective prompts the AI community to reconsider the design of benchmarks and the interpretation of results, advocating for transparency, diverse metrics, and a deeper understanding of AI’s incremental progress. The implications are clear: as we advance AI research, we must critically examine the tools of our assessment to ensure a realistic and ethical development path that aligns with societal expectations and safety standards.
Stay tuned to explore the newest findings of AI academia!
Originally published at Novita AI
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.