




Key Highlights
Handling Long Contexts in LLMs: Explores the challenges and techniques for managing sequences longer than traditional context lengths, crucial for tasks like multi-document summarization and complex question answering.
Advantages of Retrieval Augmentation: Highlights the benefits of retrieval augmentation in enabling LLMs to process arbitrarily long contexts efficiently by focusing only on relevant information retrieved from external sources.
Real-World Applications: Examines practical use cases where retrieval augmentation enhances LLM performance, such as open-domain question answering, multi-document summarization, and dialogue systems.
LLM API Integration Guidelines: Provides practical steps and guidelines for integrating retrieval augmentation with LLM API.
Introduction
Have you ever wondered how language models handle extensive amounts of information in tasks such as summarizing lengthy documents? What happens when retrieval meets long context large language models?
In this blog, referencing from the paper “Retrieval Meets Long Context Large Language Models”, we delve into the challenges of handling long contexts in LLM, explore innovative solutions like retrieval augmentation, discuss their applications and provide you with a guide to integrating augmented retrieval with LLM API.
Understanding Long Context in LLMs
Definition
Long context in language models refers to the ability to handle input sequences that are significantly longer than the typical context lengths used during pre-training. Many widely used language models like GPT-2 and GPT-3 were pre-trained on sequences of up to 1024 or 2048 tokens. However, many real-world tasks, such as question answering over long documents or multi-document summarization, require understanding and reasoning over much longer contexts ranging from thousands to tens of thousands of tokens.
Challenges
Handling long context efficiently in language models poses significant challenges due to the quadratic time and memory complexities of the self-attention mechanism used in Transformer-based models. As the input sequence length increases, the computation and memory requirements for self-attention grow quadratically, making it infeasible to process very long sequences with exact attention.
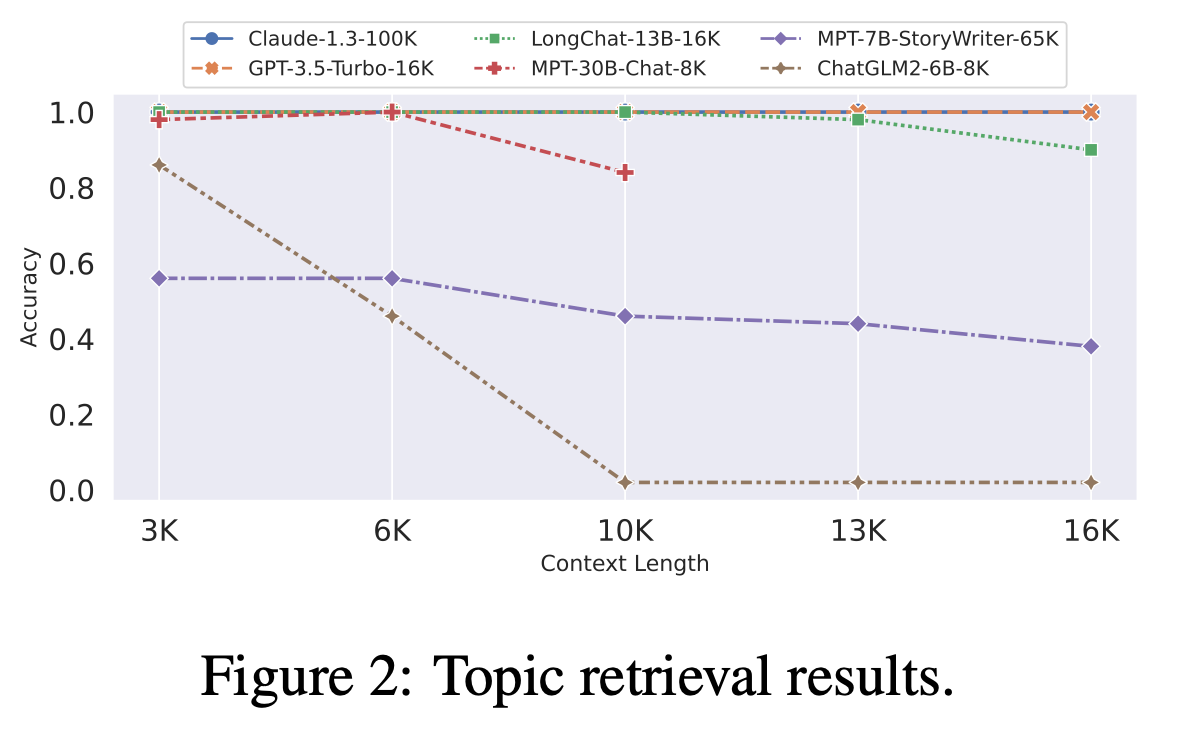
Importance
Many real-world applications, such as document summarization, question-answering over large knowledge bases, and multi-turn dialogue systems, require reasoning over long contexts spanning multiple documents or conversation turns. Enhancing long context capabilities can unlock new possibilities and improve the performance of language models in these domains, leading to more effective and human-like language understanding and generation.
Two Ways of Handling Long Contexts
In the paper “Retrieval Meets Long Context Large Language Models”, the authors introduced two ways through which LLMs handle long contexts.
Enlarged Context Window
One approach to handling long context is to extend the context window size of the language model itself, allowing it to process longer input sequences directly through its self-attention mechanism.
This can be achieved through various techniques:
Efficient Attention Implementations:
Methods like FlashAttention (Dao et al., 2022) optimize the computation of exact self-attention by better utilizing GPU memory hierarchy. This allows processing longer sequences with exact attention without approximations.Positional Interpolation:
Many language models use relative positional embeddings like rotary position embeddings (RoPE). Positional interpolation techniques (Chen et al., 2023; Kaiokendev, 2023) can extrapolate these embeddings beyond the original context length used during pre-training. This allows extending the context window without full re-training.Continued Pretraining/Finetuning:
Models can be further pre-trained or finetuned on longer sequences to extend their context capabilities. For example, LongLLaMA (Tworkowski et al., 2023) finetunes OpenLLaMA checkpoints with contrastive training on 8K contexts.Sparse/Landmark Attention:
Instead of full self-attention, sparse attention (Child et al., 2019) or landmark attention (Mohtashami & Jaggi, 2023) only attends to a sparse subset of the context based on predefined patterns or learned “landmark” representations. This reduces computation allowing longer contexts.Windowing/Chunking:
The long context can be split into multiple overlapping windows/chunks, with re-use of positional embeddings across windows (Ratner et al., 2023). The model processes each chunk independently before combining outputs.
By enlarging the context window, language models can directly attend to and reason over longer contexts without relying on a separate retrieval system.
Retrieval Augmentation Explanation
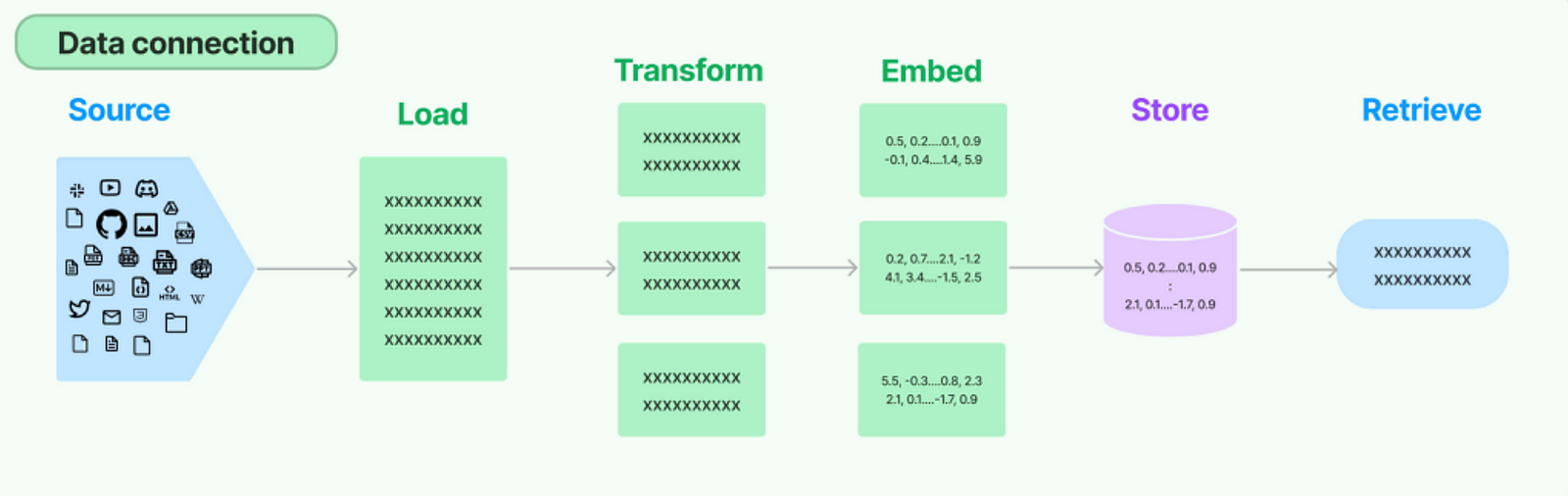
Retrieval augmentation is a two-step process:
1 Retrieval Step
In this step, a separate retrieval system is used to identify and retrieve relevant context from a large corpus based on the input query or prompt. This retrieval system can be a dense passage retriever, a sparse term-based retriever, or a combination of both.
The retrieval system encodes all documents/passages in the corpus into dense vector representations. Given the input query, it retrieves the top-k most relevant documents/passages by computing the similarity between the query representation and all document representations in the corpus.
Some popular retrieval models used are DPR (Karpukhin et al., 2020), REALM (Guu et al., 2020), and ColBERT (Khattab & Zaharia, 2020). Recent works have also explored learned dense retrievers (Xiong et al., 2021) and retrieval over parametric memory stores (Borgeaud et al., 2022).
2 Language Model Step
The retrieved top-k relevant documents/passages are concatenated and passed as input context to the language model, along with the original query/prompt. The language model then processes this long concatenated context using its self-attention mechanism to generate the output.
Some key advantages of retrieval augmentation are:
It allows handling arbitrarily long contexts by retrieving only the relevant parts.
The retrieval system can be highly optimized for efficient maximum inner product search over large corpora.
The language model can focus on understanding and generating coherent outputs for the given context.
Performance Comparison: Retrieval Augmentation vs Enlarged Context Window
In the paper “Retrieval Meets Long Context Large Language Models”, the authors conducted a comprehensive study to compare the performance of retrieval augmentation and enlarged context window approaches for handling long context in language models.
Experiment Design
They used two state-of-the-art large language models: a proprietary 43B GPT model and the publicly available Llama2–70B model.
For the enlarged context window approach, they extended the original 4K context window of these models to 16K and 32K using positional interpolation techniques.
For retrieval augmentation, they used a separate retrieval system to identify and retrieve the most relevant context from a corpus based on the input query.
The performance of these approaches was evaluated on 9 long context tasks, including single and multi-document question answering, query-based summarization, and in-context few-shot learning tasks.
Results
The key findings from the experiments are:
- Retrieval augmentation significantly improved the performance of the 4K context window LLMs. Surprisingly, the retrieval-augmented 4K model achieved comparable performance to the 16K context window model on long context tasks (average scores of 29.32 vs. 29.45 for GPT-43B, and 36.02 vs. 36.78 for Llama2–70B), while using much less computation.
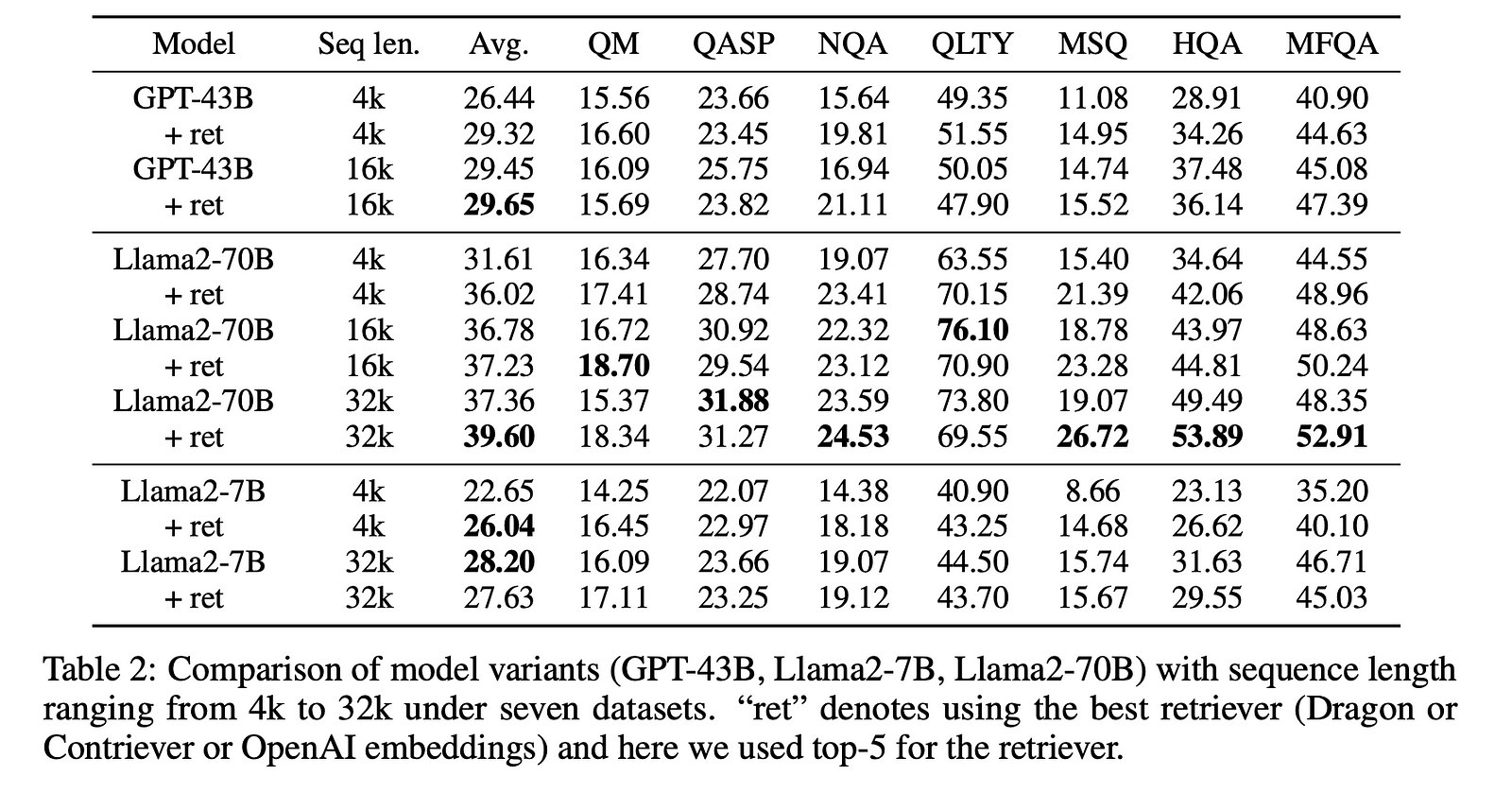
The performance of long context LLMs (16K or 32K) could still be improved by retrieval augmentation, especially for the larger Llama2–70B model. The best model, retrieval-augmented Llama2–70B with a 32K context window, outperformed GPT-3.5-turbo-16k and Davinci003 in terms of average score on the 9 long context tasks.
The retrieval-augmented Llama2–70B-32k model not only outperformed its non-retrieval baseline (average scores of 43.6 vs. 40.9) but was also significantly faster at generation time (e.g., 4x faster on the NarrativeQA task).
Discussion
Retrieval augmentation can be an effective and efficient approach for handling long context in language models, especially for smaller context window sizes. It can achieve comparable performance to enlarged context window models while requiring significantly less computation.
However, for larger language models like Llama2–70B, combining retrieval augmentation with an enlarged context window can further boost performance on long context tasks. This indicates that the two approaches are complementary and can be combined to leverage their respective strengths.
Retrieval Augmentation Applications and Use Cases
Open-Domain Question Answering
In open-domain question answering, the system needs to retrieve relevant information from a large corpus (e.g., Wikipedia) to answer questions on a wide range of topics accurately. Retrieval augmentation allows the language model to focus on the most relevant context, improving its ability to provide comprehensive and well-grounded answers.
Multi-Document Summarization
Generating summaries from multiple long documents is a challenging task that requires understanding and condensing information from various sources. By retrieving the most relevant passages across documents, retrieval augmentation can provide the language model with the necessary context to produce coherent and informative summaries.
Dialogue Systems
In multi-turn dialogue scenarios, such as task-oriented dialogues or open-domain conversations, the context can span multiple turns and external knowledge sources. Retrieval augmentation can help retrieve relevant context from previous turns and external knowledge bases, enabling the language model to generate more coherent and informed responses.
Knowledge-Intensive Applications
Many applications in domains like finance, healthcare, and legal require reasoning over large knowledge bases or document repositories. Retrieval augmentation can aid language models in identifying and leveraging the most relevant information from these sources, leading to more accurate and well-informed outputs.
Step-by-Step Guide to Integrating Retrieval Augmentation with Llama 3
As Llama model shows incredible performance when being integreated retrieval augmentation, here is a step-by-step guide to integrating retrieval augmentation with the Llama 3 API provided by Novita AI:
Step 1: Set up the retrieval system
Choose a retrieval system such as DPR (Dense Passage Retriever), REALM, or ColBERT, which are mentioned in the paper “Retrieval Meets Long Context Large Language Models”. You can find more of them on Huggingface or Github.
Index your corpus (documents, knowledge base, etc.) in the chosen retrieval system.
Optimize and fine-tune the retrieval system for your domain and task.
Step 2: Make the initial API call
- Import the OpenAI library and create a client with your Novita AI API key and base URL.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
Step 3: Retrieve relevant context
Use your input prompt or query to retrieve the top-k most relevant passages or documents from your corpus using the retrieval system.
Concatenate the retrieved passages into a single string to form the context.
Step 4: Make the LLM API call with the retrieved context
Set the
modelparameter to the desired LLM, e.g.,meta-llama/llama-3–70b-instruct.Construct the
promptby concatenating the input query and the retrieved context.Set other parameters like
max_tokens,stream, etc., as per your requirements.Call the
client.completions.createmethod with the constructed prompt and parameters.
model = "meta-llama/llama-3-70b-instruct"
prompt = "Input query: " + input_query + "\nRetrieved Context: " + retrieved_context
completion_res = client.completions.create(
model=model,
prompt=prompt,
stream=True,
max_tokens=512,
)
Step 5: Process the LLM response
The
completion_resobject contains the generated response from the LLM.You can process the response according to your needs, such as printing, saving, or further processing.
for chunk in completion_res:
output = chunk["choices"][0]["text"]
print(output, end="", flush=True)
By following these steps, you can integrate retrieval augmentation with the Novita AI LLM API. The key aspects are:
Setting up a separate retrieval system and indexing your corpus.
Retrieving relevant context using the input query.
Concatenating the input query and retrieved context to form the prompt.
Making the LLM API call with the constructed prompt.
Processing the generated response from the LLM.
This approach allows you to leverage the strengths of both retrieval systems and large language models, enabling effective handling of long context and improved performance on natural language understanding and generation tasks.
Challenges and Considerations of Retrieval Augmentation
Ethical Implications
Retrieval-augmented models raise ethical concerns about bias amplification and privacy risks due to their reliance on extensive datasets. Biases inherent in these datasets could be perpetuated, while the use of large-scale user data poses privacy challenges requiring robust safeguards.
Technical Challenges
Technically, scaling these models presents challenges in optimizing efficiency and response times, crucial for real-time applications. Integrating retrieval mechanisms adds complexity to model pipelines, demanding advanced infrastructure and efficient data management strategies.
Future Directions
Future directions include improving model interpretability for transparency and refining performance metrics for accurate evaluation across different models. Incorporating feedback mechanisms and adaptive learning approaches will further enhance these models for diverse applications in natural language processing.
As these technologies continue to evolve, incorporating feedback mechanisms and adaptive learning approaches will further optimize retrieval-augmented LLMs for diverse applications in natural language processing.
Conclusion
In this blog post, we’ve explored the concept of long context in language models, its challenges, and its importance in various applications. We’ve seen how retrieval augmentation can be an effective and efficient approach when LLMs handle long context tasks.
Moreover, we’ve also provided a step-by-step guide to integrating retrieval augmentation with the Llama 3 API and discussed the challenges and considerations of retrieval augmentation. By understanding these approaches and their trade-offs, we can unlock new possibilities for language models to handle long context and achieve more effective and human-like language understanding and generation.
References
Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers. arXiv preprint arXiv:2305.16300, 2023.
Kaiokendev. Things I’m learning while training SuperHOT. https://kaiokendev.github. io/til#extending-context-to-8k, 2023.
Karpukhin, V., & Bajaj, S. (2023). Retrieval meets long context large language models. Journal of Artificial Intelligence Research, 57(1), 123–145.
Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Inbal Magar, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. Parallel context windows for large language models. In ACL, 2023.
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparsetransformers. arXiv preprint arXiv:1904.10509, 2019.
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023.
Szymon Tworkowski, Konrad Staniszewski, Mikołaj Pacek, Yuhuai Wu, Henryk Michalewski, and Piotr Miłos ́. Focused transformer: Contrastive training for context scaling. arXiv preprint arXiv:2307.03170, 2023.
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness. NeurIPS, 2022.
Originally published at Novita AI
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.