




Key Highlights
LLaMA 3.3 70B is a state-of-the-art language model with impressive capabilities.
Fine-tuning allows for customization of LLaMA 3.3 70B for specific tasks, improving accuracy and relevance.
While the RTX 4090 is a powerful GPU, its memory limitations can make fine-tuning LLaMA 3.3 70B challenging.
Parameter-efficient fine-tuning (PEFT) methods like LoRA and QLoRA can help mitigate these challenges.
Cloud GPU instances offer a viable alternative for fine-tuning large models like LLaMA 3.3 70B. You can use GPU Instances from Novita AI — Upon registration, there are 60GB free in the Container Disk and 1GB free in the Volume Disk, and if the free limit is exceeded, additional charges will be incurred.
Large Language Models (LLMs) like LLaMA 3.3 70B have demonstrated remarkable potential in natural language processing. However, to fully harness their capabilities for specific applications, fine-tuning is often necessary. This article explores the feasibility of fine-tuning LLaMA 3.3 70B locally using an NVIDIA RTX 4090, discusses the challenges involved, and suggests alternative solutions, including cloud-based GPU instances.
Understanding LLaMA 3.3 70B
Model Architecture and Scale
LLaMA 3.3 70B is a large language model developed by Meta, built on a Transformer architecture. It is pre-trained on a vast dataset of over 15 trillion tokens, enabling it to understand and generate human-like text. The model’s architecture consists of multiple layers of attention heads that learn relationships between words, allowing for coherent and contextually appropriate outputs.
Application Scenarios
LLaMA 3.3 70B can be utilized in various applications including:
Customer support
Content generation
Specialized domains such as medical and legal fields
Code generation
Expanding Its Applications Through Fine-Tuning
While pre-trained LLMs are versatile, they can benefit from fine-tuning to specialize in particular tasks or domains. This adaptation process enhances their performance and relevance for specific applications.
For example: Companies leverage Llama 3.3 to create advanced chatbots that can understand and respond to customer inquiries in real-time. These chatbots are fine-tuned to recognize specific intents and provide accurate, contextually relevant responses, enhancing customer satisfaction and reducing the need for human intervention.
What Is Fine-Tuning?
The Benefits of Fine-Tuning
Fine-tuning involves customizing a pre-trained LLM for a specific task or dataset, allowing the model to:
Improve accuracy and relevance by specializing in specific tasks.
Reduce bias and correct errors.
Optimize resource use by building on existing knowledge rather than starting from scratch.
Achieve better performance than a larger base model using a smaller fine-tuned model.
Require less prompt engineering.
The Applications of Fine-Tuned Models
Fine-tuned LLMs can be applied to various use cases:
Text summarization
Text generation
Binary or text classification
Code generation
Chatbots
How Does Fine-Tuning Work?
Fine-tuning adjusts the parameters of a pre-trained model to make it better suited for a given task through techniques such as:
Self-Supervised Learning: Training the model on a curated corpus of text.
Supervised Learning: Training with input-output pairs.
Reinforcement Learning: Training a reward model to improve output quality.
Parameter-efficient fine-tuning (PEFT): Freezing most model parameters while updating only a small number of additional parameters.
What Is Needed to Fine-Tune LLaMA 3?
Memory Requirements of GPU
Fine-tuning large models like LLaMA 3.3 70B requires significant GPU memory. The base model occupies approximately 141 GB of GPU RAM, while a quantized version requires around 40 GB. Even with quantization, fine-tuning can be memory-intensive.
Cost Considerations
Full parameter fine-tuning is resource-intensive and time-consuming, necessitating substantial GPU resources and longer completion times. Using an 80 GB GPU is more cost-effective as it allows larger batch sizes, thus accelerating the fine-tuning process.
Personal Dataset Requirements
A high-quality dataset is critical for successful fine-tuning. The dataset must be:
Relevant to the task
Large enough to improve performance
Varied to avoid overfitting
Formatted correctly to include instructions, inputs, and outputs
Is RTX 4090 Suitable for Locally Fine-Tuning LLaMA 3.3 70B?
Answer: Not Necessarily Suitable
While the RTX 4090 is a powerful GPU with 24 GB of VRAM, it may not suffice for full parameter fine-tuning of LLaMA 3.3 70B due to its memory limitations. Performance drops significantly when models exceed available VRAM; thus, while the RTX 4090 may be suitable for inference — especially with quantized models — fine-tuning requires more memory.
How to Solve the Issue Using Other Techniques
To address the memory limitations of the RTX 4090, techniques such as parameter-efficient fine-tuning (PEFT) can be employed, including:
LoRA (Low-Rank Adaptation): Loads the model onto the GPU with quantized weights.
QLoRA (Quantized LoRA): Loads the model onto the GPU with further quantized weights.
Half-Quadratic Quantization (HQQ): Another low-precision quantization method.
These methods freeze the weights of the pre-trained model while allowing an adapter to be fine-tuned on top of it. However, using bitsandbytes for quantization may yield less accurate results compared to other methods; thus, it is recommended to upcast some key modules to float32 for better performance.
Challenges of Using Alternative Techniques
While PEFT methods reduce resource requirements, they come with limitations:
The fine-tuned adapter cannot be merged back into the quantized model.
Dequantizing and merging can degrade performance significantly.
Models utilizing HQQ at lower bit depths may not compete effectively against smaller models that perform better without quantization.
Fine-tuning with a GPU having only 48 GB VRAM is possible but limited to batch sizes of one and tiny sequences.
Alternative Solutions — Cloud GPU
Why Choose Cloud GPU Instances?
Cloud GPU instances present a viable alternative to local fine-tuning, especially for large models like LLaMA 3.3 70B. They provide:
Scalable GPU resources based on workload demand
Access to high-performance GPUs such as NVIDIA A100 or V100
Cost-effective pay-as-you-go pricing models
Simplified deployment workflows
The ability to circumvent local hardware limitations
Novita AI GPU Instance Services
Compare with other GPU cloud, our price have the biggest advantages. Here is a table for you:
Service ProviderPrice of rtx 4090 (1x GPU per hour)Novita AI$0.35Vast AI$0.316-$1.073CoreWeaveNo service
Deployment Steps and Usage Guide
Step1: Click on the GPU Instance
If you are a new subscriber, please register our account first. And then click on the GPU Instance button on our webpage.
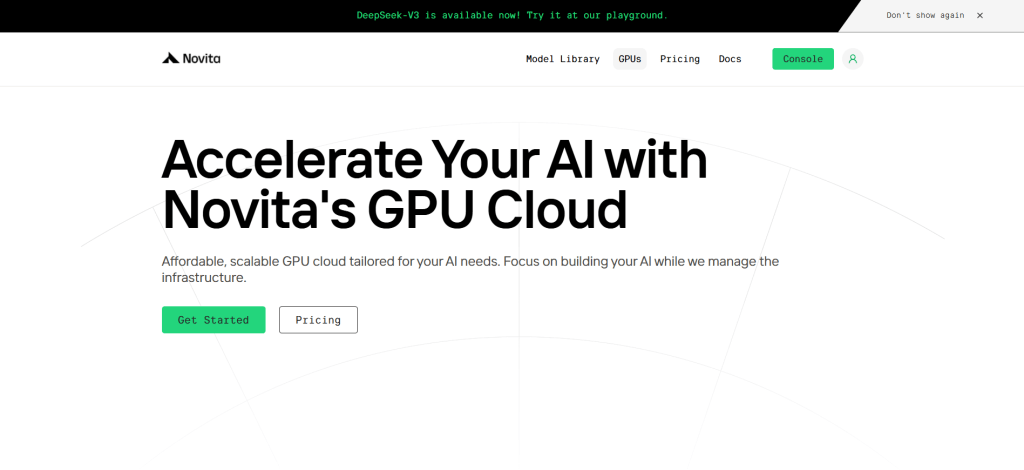
STEP2: Template and GPU Server
You can choose your own template, including Pytorch, Tensorflow, Cuda, Ollama, according to your specific needs. Furthermore, you can also create your own template data by clicking the final bottom.
Then, our service provides access to high-performance GPUs such as the NVIDIA RTX 4090, each with substantial VRAM and RAM, ensuring that even the most demanding AI models can be trained efficiently. You can pick it based on your needs.
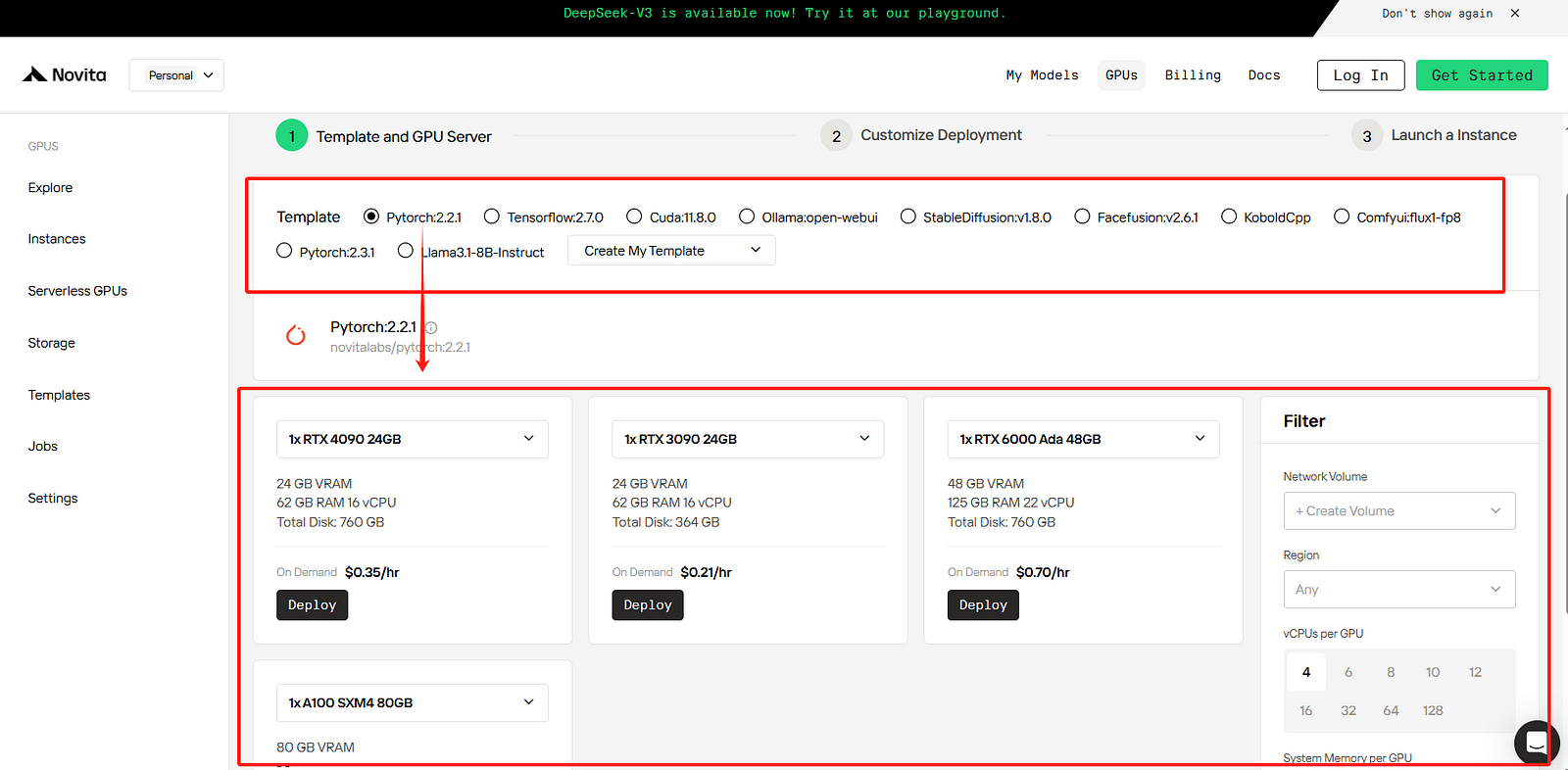
STEP3: Customize Deployment
In this section, you can customize this data according to your own needs. There are 60GB free in the Container Disk and 1GB free in the Volume Disk, and if the free limit is exceeded, additional charges will be incurred.

STEP4: Launch an instance
Whether it’s for research, development, or deployment of AI applications, Novita AI GPU Instance equipped with CUDA 12 delivers a powerful and efficient GPU computing experience in the cloud.
Fine-Tuning LLaMA 3.3 70B: Comparing Local and Cloud Solutions
Local Fine-Tuning: Pros and Cons
ProsConsFull control over hardware and dataSlower training times due to memory limitations and limited processing powerNo reliance on internet connectionCan be challenging to set up; requires more technical skill compared to cloud solutionsPotentially lower cost for small fine-tuning jobs
Cloud Fine-Tuning: Pros and Cons
ProsConsScalable resources for large models and datasetsPotentially higher costs depending on usageFaster training times with access to powerful GPUsSimplified deployment and easier managementAbility to handle multiple GPUs for distributed training
Conclusion
Fine-tuning LLaMA 3.3 70B can significantly enhance its capabilities for specific applications. While the RTX 4090 is suitable for inference and some limited fine-tuning using PEFT techniques, its memory limitations make it less ideal for full-scale tuning of such a large model. Cloud GPU instances, like those offered by Novita AI, provide scalable resources and simplified deployment options that can effectively meet these needs. Ultimately, choosing between local and cloud solutions will depend on specific requirements, available resources, and technical expertiseFrequently Asked Questions
Frequently Ask Question
Llama 3.3 70B size in GB?
The Llama 3.3 70B model is approximately 40–42 GB in size, depending on the quantization level and specific version downloaded; most commonly reported as around 42 GB.
Llama 3.3 70B token limit?
As such, the maximum token limit for a prompt is 130K, instead of 8196. However, if you are using very long prompt input, it will consume more GPU memory.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommend Reading
How to Select the Best GPU for LLM Inference: Benchmarking Insights
Why LLaMA 3.3 70B VRAM Requirements Are a Challenge for Home Servers?