




Learn how to set up your local LLM effectively with our step-by-step guide. Get started on your local llm journey today.
Key Highlights
Setting up a local language model(LLM) allows to have full control over your data and avoid sending it to external applications
Running LLMs locally is easier than you might think, and the hardware requirements are not too demanding
There are several options available for running LLMs on your own machine, including GPT4All, LLM by Simon Willison, Ollama, h2oGPT, and PrivateGPT
Each option has its own unique features and advantages, so you can choose the one that best suits your needs
By following the installation guides and integrating LLMs with your projects, you can start leveraging the power of large language models for various applications
FAQs: How to scale LLM deployments locally? Can LLMs be used without internet access? What are the costs associated with running LLMs locally?
Introduction
Chatbots have become increasingly popular in various industries, offering a convenient way to interact with users and provide assistance. However, there may be instances where you want to avoid sharing your data with external applications or platforms. In such cases, setting up a local language model (LLM) on your own machine can be a great solution.
Running LLMs locally gives you complete control over your data and ensures that it remains private and secure. You don’t have to worry about your interactions being reviewed by humans or used to train future models. Additionally, running LLMs locally allows you to try out new specialty models and experiment with different applications.
Contrary to what you might think, setting up a local LLM is not as complicated as it seems. With the right tools and resources, you can easily install and run LLMs on your own machine. In this guide, we will walk you through the process of setting up your local LLM, from understanding the basics to selecting the right model for your needs, and finally integrating it with your projects.
Understanding Local Large Language Models (LLMs)
Large Language Models (LLMs) are advanced AI models that excel at natural language tasks. Running LLMs locally offers control and privacy. It allows you to harness the power of these models directly on your system. By understanding local LLMs, you grasp the potential of deploying them within your projects. These models eschew the need for constant internet connectivity, making them ideal for sensitive data handling. Leveraging local LLMs translates to optimal performance tailored to your specific requirements. Embrace the flexibility and customization that deploying LLMs locally can provide, empowering you to take your AI initiatives to new heights.
Benefits of Running LLMs Locally
(Security concerns, Cloud workstations, Latency)
Running LLMs locally offers several benefits over using cloud-based services or external applications.
One of the main advantages is enhanced security. By running the model on your own machine, you have complete control over your data and can ensure that it remains private and secure. This is particularly important for sensitive information or proprietary data.
Another benefit is the reduced latency. When you run the LLM locally, there is no need to send data to external servers, which can cause delays in processing and response times. This is especially important for real-time applications or use cases where quick responses are required.
Additionally, running LLMs locally allows you to leverage the power of your own hardware without relying on cloud resources. This can result in cost savings and improved performance, especially if you have high-performance GPUs or specialized hardware.
Preparing Your System for LLM
(Hardware requirements, Software dependencies, System setup)
Before you can start running LLMs locally, you need to ensure that your system meets the necessary requirements and has the required software dependencies installed.
In terms of hardware, you may need a powerful GPU, especially for more resource-intensive models. However, some models can also be run on systems with lower specifications, such as a regular desktop or a laptop.
Regarding software dependencies, you will typically need to have Python, Docker, and an API key installed. These dependencies will enable you to install and run the LLM models on your machine.
Once you have the necessary hardware and software in place, you can proceed with selecting the right LLM for your needs.
Hardware Requirements and Recommendations
(GPU, GPUs, Mac, Server)
The hardware requirements for running LLMs locally can vary depending on the specific model and its resource demands. Some LLMs may require a powerful GPU, while others can run on systems with lower specifications.
If you are planning to work with resource-intensive models or large-scale applications, a high-performance GPU is recommended. This will ensure faster processing and better performance. However, if you are working on smaller projects or experimenting with simpler models, a regular desktop or laptop may suffice.
It’s worth noting that some models are optimized for specific hardware configurations, such as Macs or servers. If you have a specific hardware setup, be sure to check if the LLM model you intend to use is compatible with your system.
Software Dependencies for LLM Installation
(Python, Docker, API key)
To install and run LLMs locally, you will need to have certain software dependencies installed on your machine.
Python is a popular programming language used in the machine learning community. It provides a wide range of libraries and tools that make it easy to work with LLMs. Ensure that Python is installed on your system before proceeding with the installation of LLM models.
Docker is a platform that allows you to package and distribute software applications in containers. It provides a consistent environment for running LLM models and their dependencies. Install Docker on your machine to ensure seamless installation and execution of LLM models.
Lastly, you may need an API key to access certain LLM models or platforms. This key will authenticate your requests and allow you to interact with the LLM models.
Once you have these software dependencies in place, you can proceed with selecting the right LLM for your needs.

Selecting the Right LLM for Your Needs
(Open source LLMs, LLM models, Performance metrics)
There are various LLM models available for different applications and use cases. When selecting the right LLM for your needs, consider factors such as performance metrics, compatibility with your system, and specific features required for your project.
Open source LLMs, in particular, offer a wide range of models that are freely available and can be customized to suit your requirements. These models are constantly evolving and improving, with the community contributing to their development.
By understanding the performance metrics and features of different LLM models, you can make an informed decision and choose the one that best aligns with your goals.
Overview of Popular LLM Platforms
(OpenAI, Google, Novita AI)
There are several popular LLM platforms that offer a range of models and resources for running LLMs locally.
OpenAI, for example, provides access to a variety of pre-trained models, including the widely known GPT-3. They also offer an API that allows you to interact with their models remotely.

Google Cloud is another platform that offers LLM models and resources for running them locally. They provide a range of tools and services to support LLM development and deployment.
novita.ai is a one-stop platform for limitless creativity that gives you access to 100+ APIs, including LLM APIs. Novita AI provides compatibility for the OpenAI API standard, allowing easier integrations into existing applications.
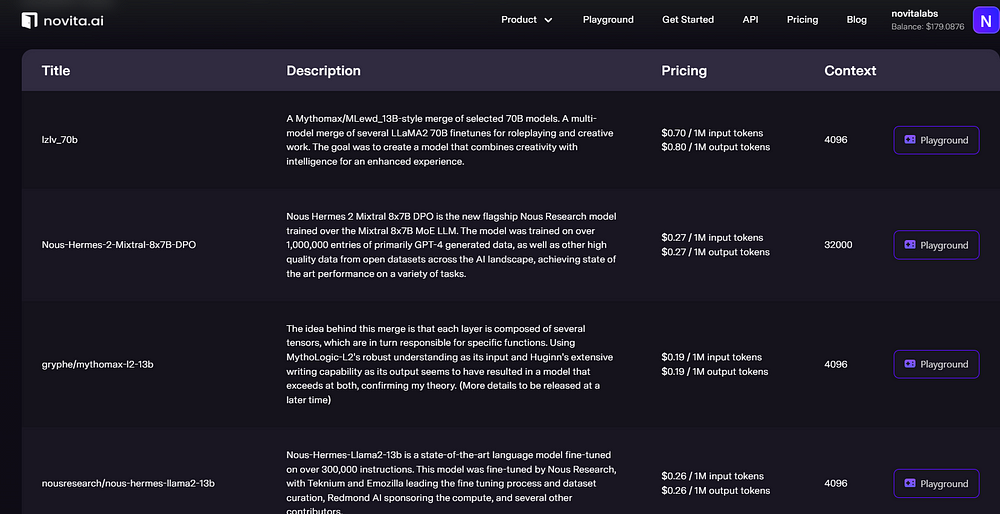
By exploring these platforms and their offerings, you can find the right LLM model for your needs.
Comparing Performance and Features
(Inference, Metrics, Tokens, Features)
When comparing different LLM models, it’s important to consider their performance and features.
Performance metrics such as inference time, accuracy, and resource usage can give you an idea of how well a model performs for a specific task. Look for models that have been benchmarked and evaluated against industry standards.
Another factor to consider is the number of tokens supported by the model. Models with higher token limits can handle longer inputs and generate more detailed responses.
Additionally, consider the specific features offered by each model. Some models may have specialized capabilities, such as code generation or translation, that align with your project requirements.
By comparing the performance and features of different LLM models, you can make an informed decision and select the best option for your needs.
Installation Guide for Local LLMs
(Command line, Installation process, Documentation)
Once you have selected the right LLM for your needs, you can proceed with the installation process. Each LLM platform or model may have its own installation guide, so be sure to refer to the documentation provided.
Most installations involve using the command line interface to download the necessary files and dependencies. The installation process typically includes steps such as downloading the model, setting up the required environment, and configuring any additional settings or plugins.
Follow the step-by-step instructions provided in the documentation to ensure a successful installation. If you encounter any issues or errors, refer to the troubleshooting section or consult the community forums for assistance.
Step-by-Step Installation Process
(Terminal, macOS, Setup, Readme)
The installation process for local LLMs may vary depending on the specific platform or model you are using. However, the general steps usually involve using the terminal or command line interface to download and set up the necessary files and dependencies.
Start by opening the terminal or command prompt on your machine. Navigate to the directory where you want to install the LLM files.

Next, follow the instructions provided in the documentation or readme file to download the model and any required dependencies. This may involve running specific commands or scripts to set up the environment and configure the model.

Once the installation is complete, you can test the LLM by running a sample query or interacting with the model through the provided interface.

If you encounter any issues during the installation process, refer to the troubleshooting section in the documentation or seek help from the community forums.
Troubleshooting Common Installation Issues
(Troubleshooting, Query, Error, Docs)
During the installation process of local LLMs, you may encounter common issues or errors that can be easily resolved with some troubleshooting. Here are some common installation issues and their potential solutions:
Error: Dependency not found
Solution: Check that all the required dependencies are installed and properly configured. Make sure you have followed the installation steps correctly.
Error: Configuration file not found
Solution: Double-check that you have downloaded all the necessary files and placed them in the correct directories. Refer to the documentation or readme file for specific instructions.
Error: Model not responding to queries
Solution: Ensure that the model is running and properly configured. Test it with a simple query to verify if it is functioning correctly.
If you are unable to resolve the issue, consult the documentation or seek help from the community forums. Often, others have encountered similar problems and can provide guidance or solutions.
Integrating LLM with Your Projects
(Desktop application, API, Integration, Projects)
Once you have successfully installed and set up your local LLM, you can start integrating it with your projects.
For desktop applications, you can leverage the capabilities of the LLM by incorporating it into the application’s codebase. This allows you to provide users with enhanced features and functionalities powered by the LLM.
Alternatively, you can use the LLM’s API to integrate it with other applications or systems. This enables seamless communication and data exchange between your project and the LLM.
By integrating LLMs with your projects, you can leverage their power and capabilities to enhance the user experience and provide advanced functionality.
Connecting LLM to Existing Applications
(API, App, Browser, SSH)
To connect your local LLM to existing applications, you can use the LLM’s API. The API allows your application to send requests to the LLM and receive responses.
You can integrate the LLM API into your application’s codebase using the programming language of your choice. This enables your application to interact with the LLM and leverage its capabilities.
You can also connect the LLM to applications through a browser interface. This allows users to directly interact with the LLM and receive responses in real-time.
Additionally, you can connect to the LLM through SSH, enabling remote access and control. This allows you to execute commands and queries on the LLM from a remote location.
By connecting the LLM to existing applications, you can extend their functionality and provide enhanced features powered by the LLM.
Developing New Applications with LLM
(Development, Repositories, Open source)
If you want to develop new applications using LLMs, you can leverage open source repositories and resources available in the community.
Open source repositories, such as those hosted on GitHub, provide a wealth of LLM models, code samples, and resources that you can use to kickstart your development process. These repositories often have detailed documentation and community support, making it easier to get started with LLM development.
You can also contribute to the open source community by sharing your own LLM models, code snippets, or documentation. This helps foster collaboration and innovation in the field of LLM development.
By leveraging open source resources and actively participating in the community, you can develop new applications with LLMs and contribute to the advancement of the field.
Conclusion
In conclusion, setting up your local LLM can significantly enhance your language model capabilities. Understanding the benefits, hardware requirements, selecting the right LLM, and seamlessly integrating it with your projects are essential steps to maximize its potential. By following a step-by-step installation guide and troubleshooting common issues, you can ensure a smooth setup process. Frequently asked questions about scaling deployments and costs should also be considered for a comprehensive understanding. Embrace the power of local LLMs to elevate your language processing efficiency and stay ahead in this digital age.
Frequently Asked Questions
How to Scale LLM Deployments Locally?
Scaling LLM deployments locally involves optimizing the hardware resources and infrastructure to handle larger workloads. This can be achieved by using more powerful servers or GPUs, distributing the workload across multiple machines, and implementing efficient resource management techniques.
Can I Use LLMs Without Internet Access?
Yes, you can use LLMs without internet access by running them locally on your own machine. This ensures that your data remains on your local system and is not transmitted over the internet. It also addresses security concerns related to data privacy and confidentiality.
What Are the Costs Associated with Running LLMs Locally?
The costs associated with running LLMs locally include the initial investment in hardware, such as GPUs or high-performance machines, software licenses, and ongoing maintenance and updates. The exact costs will vary depending on the specific LLM models and hardware requirements.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.