




Dive yourself into the intricate world of large language models (LLMs), their applications, and the ethical considerations they bring to industries such as healthcare, finance, and technology. Learn how these advanced AI models work, their benefits, potential risks, and the future of artificial intelligence in processing and understanding natural language.
Introduction
In the rapidly evolving field of artificial intelligence, large language models (LLMs) stand at the forefront, shaping the way we interact with digital systems. Powered by sophisticated transformer architectures, these models are revolutionizing numerous sectors by enhancing capabilities in natural language processing (NLP), sentiment analysis, and even code generation. As we delve deeper into the mechanics, applications, and ethical considerations surrounding LLMs, it is crucial to understand both their potential and limitations. This article explores the definition of LLMs, how they work, and future developments of large language models in various industries.
Here is a video about how LLM works:
https://www.youtube.com/watch?v=5sLYAQS9sWQ
Definition of Large Language Models
A large language model (LLM) is a type of deep learning algorithm equipped to handle various natural language processing (NLP) tasks. These models are built on transformer architectures and are trained with vast datasets, which allows them to perform tasks like recognizing, translating, predicting, or generating text or other content.
Often referred to as neural networks (NNs), these systems mimic the structure of the human brain, consisting of layers of interconnected nodes similar to neurons.
Beyond facilitating the learning of human languages in AI applications, large language models can also be adapted for diverse functions such as analyzing protein structures, developing software code, and more. Before they can efficiently address specific problems like text classification, question answering, document summarization, or text generation, these models require initial pre-training followed by fine-tuning.
Their ability to solve complex problems finds application in various sectors including healthcare, finance, and entertainment, aiding in tasks ranging from translation to powering chatbots and AI assistants.
Additionally, large language models possess extensive parameters, reminiscent of the model’s accumulated knowledge through training, serving as a repository of information it has learned.
What is a Transformer Model
A transformer model is a prevalent architecture used in large language models, featuring an encoder and a decoder. It processes data by breaking down the input into tokens and applying mathematical operations to identify relationships between these tokens. This method allows the model to discern patterns in a way similar to human cognition when presented with the same information.
Transformer models incorporate self-attention mechanisms, which significantly enhance their learning speed compared to traditional models, such as long short-term memory (LSTM) models. The self-attention capability allows the transformer to evaluate various parts of the input sequence or the full context of a sentence, facilitating accurate predictions.
Key components of large language models
Large language models consist of various neural network layers that collaborate to process input text and produce output content. These layers include recurrent layers, feedforward layers, embedding layers, and attention layers.
The embedding layer is responsible for converting the input text into embeddings, capturing both the semantic and syntactic meanings of the input, which helps the model grasp the context.
Feedforward layers, or FFNs, in a large language model comprise multiple fully connected layers that modify the input embeddings. This transformation allows the model to extract higher-level abstractions and understand the user’s intent behind the text input.
Recurrent layers process the words in the input text sequentially, capturing the relationships between words within a sentence to maintain a flow of context.
The attention mechanism allows the model to selectively concentrate on specific parts of the input text that are most relevant to the current task. This layer is crucial for enabling the model to generate precise and contextually appropriate outputs.
Large language models can be categorized into three primary types:
Generic or raw language models predict the next word based on the language in the training data. These language models perform information retrieval tasks.
Instruction-tuned language models are trained to predict responses to the instructions given in the input. This allows them to perform sentiment analysis, or to generate text or code.
Dialog-tuned language models are trained to have a dialog by predicting the next response. Think of chatbots or conversational AI.
How do large language models work?
A large language model operates on a transformer architecture, which involves receiving input, encoding this input, and then decoding it to generate an output prediction. However, before a large language model can effectively process text inputs and generate accurate predictions, it undergoes two crucial stages: training and fine-tuning.
Training
In the training phase, large language models are pre-trained using extensive textual datasets sourced from platforms like Wikipedia, GitHub, and others, comprising trillions of words. The quality of these datasets significantly influences the model’s performance. During training, the model engages in unsupervised learning, absorbing and analyzing the data without specific direction. This allows the model to grasp the meanings of words, the relationships between them, and context-specific usage. For example, the model learns to discern different meanings of the word “right,” such as indicating correctness or a direction.
Fine-tuning
To enable a large language model to execute particular tasks like translation, it undergoes fine-tuning, which tailors the model to optimize performance for these specific functions.
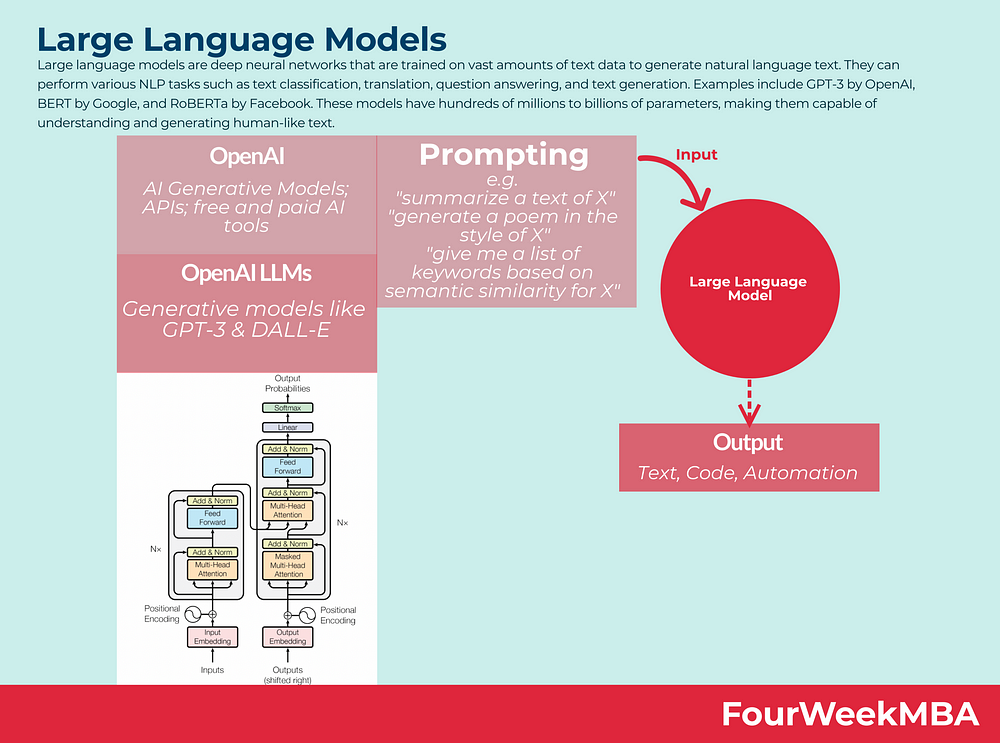
Prompt-tuning
This technique is akin to fine-tuning but focuses on training the model to undertake specific tasks through limited examples (few-shot prompting) or even without examples (zero-shot prompting). In few-shot prompting, the model is presented with examples that demonstrate the task, such as identifying sentiments from customer reviews:
Customer review: This plant is so beautiful!
Customer sentiment: positive
Customer review: This plant is so hideous!
Customer sentiment: negative
Here, the model learns the semantic implications of words like “hideous” and, through contrasting examples, understands that the sentiment in the second instance is negative.
In contrast, zero-shot prompting involves presenting tasks directly without example-based guidance. For instance, asking the model, “The sentiment in ‘This plant is so hideous’ is…,” prompts the model to perform the task of sentiment analysis directly, without providing specific examples to learn from.
Inference Engine
It is well known that there are three core factors affecting Large Language Model (LLM) performance on GPUs: (1) GPU computational power, (2) GPU input/output (I/O), and (3) GPU memory size. It’s worth noting that for today’s LLMs, factor (2) is the primary bottleneck during the inference stage.
If you are interested in how LLMs are pruned, you can find more information in our blog:
Unveiling LLM-Pruner Techniques: Doubling Inference Speed
Sparse Compiler: Unlocking New Frontiers in LLM Inference | A100 GPU Empowers Sparse Computing
Limitations and Challenges of Large Language Models
Large language models (LLMs) may seem capable of understanding and responding with high accuracy, but they are fundamentally technological tools and face numerous challenges.
Hallucinations: This term refers to instances where an LLM generates false or unrelated outputs, such as claiming to be human, experiencing emotions, or professing love for a user. These errors occur because while LLMs can predict syntactically correct sequences, they do not truly grasp human meanings, leading to these so-called “hallucinations.”

Security Risks: LLMs pose significant security concerns if not properly monitored and controlled. They can inadvertently disclose personal information, aid in phishing attacks, generate spam, or be manipulated to propagate harmful ideologies or misinformation. The potential global impact of such activities can be severe.
Bias: The data used to train LLMs influences their outputs. If the training data is not diverse or is biased towards a particular demographic, the outputs of the model will reflect these limitations, resulting in a lack of diversity in responses.
Consent and Privacy Issues: LLMs are trained on vast amounts of data, some of which may be collected without proper consent. This includes scraping data from the internet without respecting copyright laws, plagiarizing content, or using proprietary data without authorization. Such practices can lead to legal challenges, such as the lawsuit filed by Getty Images, and raise serious privacy concerns.
Scaling Challenges: Expanding and maintaining LLMs can be resource-intensive and technically demanding, requiring significant investment in terms of time and infrastructure.
Deployment Complexity: Deploying LLMs involves sophisticated requirements, including deep learning technologies, transformer architectures, and distributed computing resources, all of which necessitate a high level of technical expertise.
Existing Popular Large Language Models
GPT: The Generative Pre-trained Transformer series, developed by OpenAI, represents some of the most recognized large language models. Each new version (such as GPT-3, GPT-4) builds on the capabilities of its predecessors. These models are highly versatile and can be adapted for specific applications, such as Salesforce’s EinsteinGPT for customer relationship management and Bloomberg’s BloombergGPT for financial services.
XLNet: Distinct from BERT, XLNet is a permutation-based language model that predicts outputs in a non-sequential, random order. This approach allows it to analyze the arrangement of tokens and predict them randomly, which helps in capturing a deeper understanding of language contexts.

PaLM: Developed by Google, the Pathways Language Model (PaLM) is a transformer-based model known for its abilities in common-sense reasoning, arithmetic calculations, joke interpretation, code generation, and language translation.
BERT: Another creation from Google, the Bidirectional Encoder Representations from Transformers (BERT) model uses transformer technology to process natural language and respond to queries effectively. It is designed to comprehend natural language in a way that mimics human understanding.

novita.ai LLM: novita.aai LLM offers uncensored, unrestricted conversations through powerful Inference APIs. Novita AI LLM Inference API empowers LLM stability and low latency. LLM performance can be highly enhanced with Novita AI LLM Inference API.
Future Developments In Large Language Models
The emergence of ChatGPT has highlighted the significance of large language models and sparked intense discussions about their potential impact on the future.
As these models become more sophisticated and enhance their natural language processing capabilities, there is growing apprehension about their effects on employment. It is evident that large language models could potentially displace workers in some industries.
While in capable hands, large language models can boost productivity and streamline processes, their integration into human society raises important ethical considerations.
Conclusion
Large language models represent a significant advancement in AI technology, offering transformative potential across diverse fields. However, as their capabilities expand, so do the ethical and practical challenges they pose — from job displacement concerns to security risks. Addressing these challenges requires a balanced approach, ensuring that while we harness the benefits of LLMs, we also mitigate their risks and maintain ethical standards. As we continue to explore and innovate, the future of LLMs will undoubtedly be a pivotal aspect of technological progress, demanding careful consideration and responsible implementation.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.