




Learn how to fine-tune Large Language Models (LLMs) for chatbots effectively, optimizing their performance and enhancing user engagement. Discover crucial strategies, pitfalls to avoid, and tips for successful fine-tuning, ensuring that your chatbots deliver personalized, contextually relevant responses. Master the art of LLM optimization to create chatbots that excel in understanding and interacting with users, driving a more satisfying conversational experience.
Introduction
Have you ever pondered the seemingly remarkable ability of certain chatbots to grasp and respond to your inquiries with a level of understanding akin to conversing with a human? The secret lies in skillfully adjusting the Large Language Model (LLM). Previously, we’ve employed RAG in our blog to achieve a similar feat. Fine-tuning stands out as another approach to refining LLM responses.
In this blog post, we will explore seven crucial strategies for fine-tuning LLM to elevate chatbot proficiency. These strategies will simplify complex concepts into digestible tips accessible to all. By the conclusion of this post, you’ll have gained valuable insights into enhancing chatbot performance through effective LLM optimization.
Understand Fine-Tuning
While a pre-trained Large Language Model (LLM) possesses a wealth of general knowledge, it may require assistance in handling domain-specific questions and understanding medical terminology and abbreviations. This is where fine-tuning becomes essential.
But what does fine-tuning entail? Essentially, it involves transferring knowledge. These expansive language models undergo training on vast datasets using significant computational resources and feature millions of parameters.

The linguistic patterns and representations acquired by the LLM during its initial training are then applied to your current task. Technically, this process starts with a model initialized using pre-trained weights.
Subsequently, it undergoes training using data pertinent to your specific task, refining the parameters to better align with the task’s requirements. You also have the flexibility to adjust the model’s architecture and modify its layers to cater to your specific needs.
Why is Fine-Tuning Important for LLMs
Customizing a large language model for chatbot purposes is primarily driven by the fact that general models are adaptable but not tailored for specific tasks. Fine-tuning an AI chatbot is akin to providing personalized instruction to enhance its capabilities. This process aids the chatbot in understanding and responding to users’ individual conversational styles more effectively. The distinction lies in transitioning from a standard conversation to a tailored chat experience where individuals feel genuinely listened to and understood.
Understand How Pre-trained Language Models Work
The Language Model is a machine learning algorithm specifically crafted to predict the next word in a sentence by analyzing preceding segments. It operates on the Transformers architecture, extensively elaborated in our article detailing How Transformers function.
Pre-trained language models like GPT (Generative Pre-trained Transformer) undergo training on extensive text datasets. This equips them with a foundational understanding of word usage and sentence structure in natural language.

The pivotal aspect is that these models excel not only in comprehending natural language but also in generating text that closely resembles human writing, guided by the input they receive.
Different Types of Fine-tuning
Fine-tuning encompasses various approaches, each tailored to specific objectives and focal points.
Supervised Fine-tuning: This method involves further training the model on a labeled dataset relevant to the target task, such as text classification or named entity recognition. For example, training the model on a dataset labeled with sentiment scores for sentiment analysis tasks.
Few-shot Learning: In cases where gathering a large labeled dataset is challenging, few-shot learning comes into play. It provides a small number of examples (shots) of the task at the input prompts, aiding the model in grasping the task’s context without extensive fine-tuning.
Transfer Learning: While all fine-tuning techniques involve transfer learning to some extent, this category specifically enables a model to perform tasks different from its initial training. It leverages the knowledge acquired by the model from a broad, general dataset and applies it to a more specific or related task.
Domain-specific Fine-tuning: This approach aims to adapt the model to understand and generate text specific to a particular domain or industry. By fine-tuning the model on a dataset comprising text from the target domain, its contextual understanding and knowledge of domain-specific tasks are enhanced. For instance, training the model with medical records to develop a chatbot for a medical application, thereby adapting its language capabilities to the healthcare domain.
Tips for Fine-Tuning Your LLMs
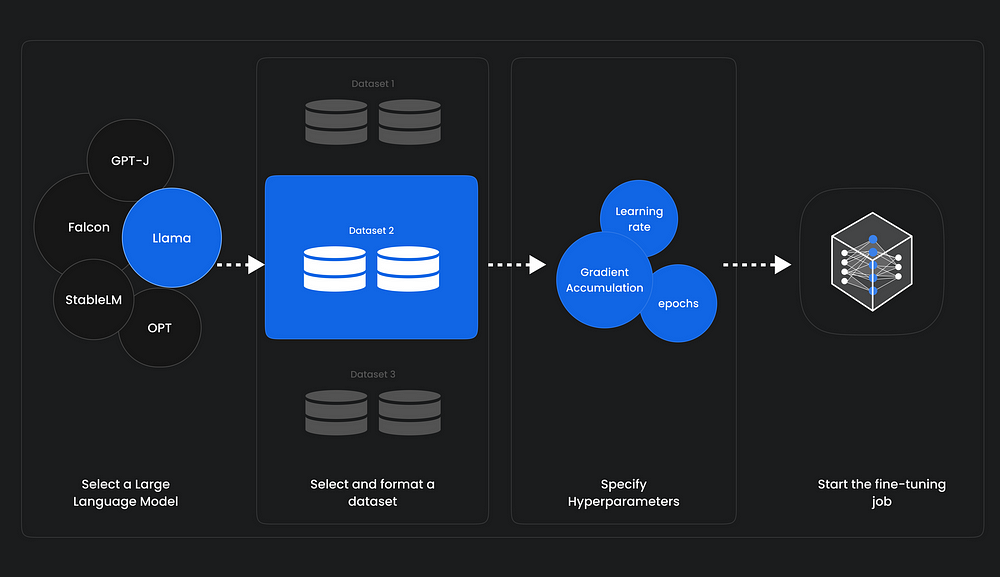
Understand Your Audience
Imagine if your chatbot spoke Shakespearean English to a teenager asking about the latest gaming trends. To effectively fine-tune your Large Language Model (LLM), you must understand your audience. Familiarize yourself with their language, preferences, and communication style. This understanding forms the foundation for training your chatbot to connect with users.
Data Preparation and Expansion
Before diving into fine-tuning an LLM for a chatbot, it’s crucial to ensure that the training data is well-prepared. This involves refining and expanding the dataset to enhance its quality and diversity. Through data cleansing and strategies like data expansion and paraphrasing, the LLM can uncover a broader range of language variations and scenarios, thereby enhancing its performance in understanding and generating responses.

Screenshot of Hugging Face Datasets Hub. Selecting OpenAI’s GPT2 model.
Domain-Specific Training
One of the most crucial aspects of fine-tuning LLM for chatbots is domain-specific training. This process involves training the language model on a dataset specific to the domain in which the chatbot will operate. For example, a customer support chatbot would benefit from refining customer service-related conversations. By fine-tuning the LLM on domain-specific data, the chatbot can better grasp the nuances of relevant topics and provide more tailored responses based on the context.
Gather and Select Quality Data
When fine-tuning LLM for chatbots, focus on quality over quantity when it comes to data collection. Instead of overwhelming the model with vast amounts of data, curate a selection of high-quality conversational data that reflects real interactions with your chatbot. Think of it as teaching your bot from the best conversational examples rather than inundating it with irrelevant information.
Hyperparameter Optimization
Fine-tuning LLM involves adjusting its hyperparameters, which significantly impact its performance. Hyperparameters govern the learning dynamics and capacity of the model, and optimizing them can enhance its generalization and response generation abilities. Techniques such as learning rate scheduling, gradient clipping, and batch size optimization are crucial for fine-tuning LLM for chatbot applications.
Evaluation and Continuous Improvement
Continuous improvement is essential for enhancing an AI chatbot’s performance over time. Establish robust evaluation metrics to assess the chatbot’s responses, including clarity, relevance, and natural language flow. Based on the results, make incremental adjustments to improve the chatbot’s ability to meet its conversational objectives.
Human Oversight
Even the most advanced chatbots benefit from human oversight. Incorporate feedback loops where real people evaluate and refine the chatbot’s responses. This not only fine-tunes the LLM for the chatbot but also ensures that it remains aligned with the dynamic nature of language and user expectations.
Tips for Avoiding LLM Fine-Tuning Pitfalls
Fine-tuning, while advantageous, can also present certain challenges that may lead to less-than-ideal outcomes. Here are some pitfalls to be mindful of:
Overfitting: Overfitting occurs when a model becomes too specialized to the training data, resulting in high accuracy on the training set but poor generalization to new data. This can happen when using a small dataset for training or excessively extending the number of training epochs.
Underfitting: Conversely, underfitting occurs when a model is too simplistic to adequately capture the underlying patterns in the data. This can result from insufficient training or a low learning rate, leading to poor performance on both the training and validation datasets.
Catastrophic Forgetting: During the fine-tuning process, there’s a risk that the model may forget the broad knowledge it acquired during its initial training. This phenomenon, known as catastrophic forgetting, can impair the model’s ability to perform well across a range of tasks in natural language processing.
Data Leakage: It’s essential to ensure that the training and validation datasets are separate and that there’s no overlap between them. Data leakage, where information from the validation set inadvertently influences the training process, can lead to misleadingly high-performance metrics.
By being aware of these pitfalls and taking appropriate precautions, such as using sufficient data for training, optimizing hyperparameters, and carefully managing datasets, you can mitigate the risks associated with fine-tuning and improve the overall performance of your models.
Successfully Fine-tuned Cases of Large Language Models
GPT: The Generative Pre-trained Transformer series, developed by OpenAI, represents some of the most recognized large language models. Each new version (such as GPT-3, GPT-4) builds on the capabilities of its predecessors. These models are highly versatile and can be adapted for specific applications, such as Salesforce’s EinsteinGPT for customer relationship management and Bloomberg’s BloombergGPT for financial services.

PaLM: Developed by Google, the Pathways Language Model (PaLM) is a transformer-based model known for its abilities in common-sense reasoning, arithmetic calculations, joke interpretation, code generation, and language translation.
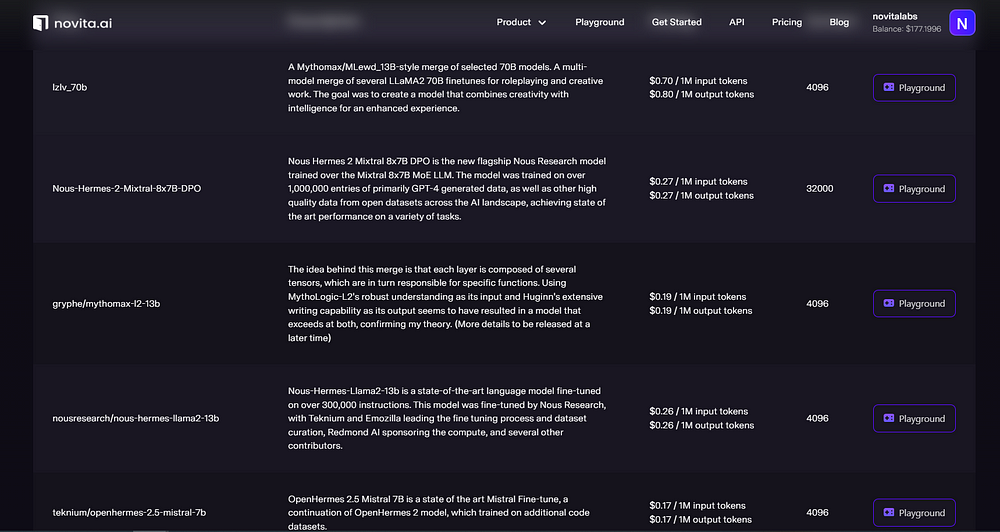
novita.ai LLM: novita.aai LLM offers uncensored, unrestricted conversations through powerful Inference APIs. Novita AI LLM Inference API empowers LLM stability and low latency. LLM performance can be highly enhanced with Novita AI LLM Inference API.
conclusion
Fine-tuning Large Language Models (LLMs) for chatbots is a powerful strategy to enhance their performance and enable more human-like interactions. By understanding the nuances of fine-tuning techniques and avoiding common pitfalls such as overfitting, underfitting, catastrophic forgetting, and data leakage, developers can optimize their chatbots for specific tasks and domains. With the ability to grasp user intent more accurately and generate contextually relevant responses, fine-tuned chatbots can provide a more personalized and satisfying user experience. Continuous evaluation, refinement, and human oversight ensure that chatbots remain aligned with evolving user expectations and language dynamics. As the demand for intelligent conversational agents grows, mastering the art of fine-tuning LLMs will be essential for creating chatbots that truly excel in understanding and engaging with users.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.