




Unleash the power of Meta Llama 3, the most advanced LLM available today. Elevate your projects with this cutting-edge tool.
Introduction
Meta AI, a leading artificial intelligence (AI) company, has unveiled its most powerful large language model (LLM) to date — Meta Llama 3. This groundbreaking model promises to revolutionize the field of AI with its advanced capabilities and performance. Llama 3 outperforms other models like Gemma 7B, Claude 3 Sonnet, and Mistral 7B in various benchmarks, making it the most capable and sophisticated LLM available in the market. The Meta Llama 3 was introduced on Thursday (April 18) and will be integrated into Meta AI’s proprietary virtual assistant, making it even more accessible to users.
Meta AI has always been at the forefront of AI innovation, and Llama 3 is a testament to their commitment to pushing the boundaries of what is possible in the field. With Llama 3, Meta AI aims to provide developers and researchers with a powerful tool that can be integrated into various applications, including their proprietary virtual assistant — Meta AI. With Llama 3’s powerful Open Source Model capacity, novita.ai’s LLM has been equipped with Meta’s latest class of model (Llama 3). Now let’s begin with the new era of Meta AI.
Unveiling Meta Llama 3: A New Era in AI
Meta Llama 3 represents a new era in AI with its advanced technology and capabilities. As a large language model, it has been trained on vast amounts of data to understand and generate human-like text. This model is a significant improvement over its predecessors, offering enhanced performance and the ability to generate high-quality content, including code generation. With Meta Llama 3, Meta AI is pushing the boundaries of what is possible in the field of AI and opening up new opportunities for developers and researchers.
here is a video clip of an introduction to Llama 3:

Goals of Meta Llama3
Meta AI developers embarked on the development of Llama 3 with the aim of creating top-tier open models comparable to the best proprietary ones currently available. Their focus has been on incorporating developer feedback to enhance the overall utility of Llama 3, all while maintaining a leading role in promoting the responsible use and deployment of large language models. Following the open source ethos, they are committed to frequent releases, allowing the community to access these models during their developmental stages. The text-based models unveiled today represent the initial offerings in the Llama 3 lineup. Looking ahead, their objective is to expand Llama 3 to support multiple languages and modalities, extend context capabilities, and continually enhance performance across essential LLM functions like reasoning and coding.
Key Features That Set Llama 3 Apart
Llama 3 possesses several key features that set it apart from other language models in the market
Model architecture
In accordance with their design philosophy, a relatively standard decoder-only transformer architecture was chosen for Llama 3. Several key enhancements were implemented compared to Llama 2. Llama 3 utilizes a tokenizer with a vocabulary of 128K tokens, resulting in more efficient language encoding and significantly improved model performance. To enhance the inference efficiency of Llama 3 models, grouped query attention (GQA) was adopted across both the 8B and 70B sizes. Models were trained on sequences of 8,192 tokens, with masking applied to ensure self-attention does not extend beyond document boundaries.
Training Data
Regarding training data, the team recognized the importance of a large, high-quality dataset. Consequently, substantial investment was made in pretraining data curation. Llama 3 is pretrained on over 15 trillion tokens sourced from publicly available data, seven times larger than the dataset used for Llama 2, and includes four times more code. In preparation for multilingual applications, over 5% of the pretraining dataset consists of high-quality non-English data spanning more than 30 languages.
To maintain data quality, a series of data-filtering pipelines were developed, incorporating heuristic filters, NSFW filters, semantic deduplication methods, and text classifiers. Interestingly, previous iterations of Llama proved effective in identifying high-quality data, with Llama 2 utilized to generate training data for text-quality classifiers powering Llama 3.
Extensive experimentation was conducted to optimize data mixing from various sources for the final pretraining dataset, ensuring robust performance across diverse use cases such as trivia questions, STEM, coding, and historical knowledge.
Scale up
To effectively harness the pretraining data for Llama 3 models, significant efforts were directed towards scaling up the pretraining process. A comprehensive set of scaling laws was meticulously developed to guide downstream benchmark evaluations. These laws empowered the team to select an optimal data mix and make well-informed decisions regarding the utilization of training compute resources. Notably, the scaling laws enabled the prediction of the performance of the largest models on key tasks, such as code generation, before the actual training commenced. This proactive approach ensured robust performance across various use cases and capabilities.
Throughout the development of Llama 3, novel observations regarding scaling behavior were made. For instance, while the optimal amount of training compute for an 8B parameter model corresponds to approximately 200B tokens, it was discovered that model performance continued to improve even after training on significantly larger datasets. Both the 8B and 70B parameter models exhibited log-linear improvements even after being trained on up to 15 trillion tokens. Although larger models can match the performance of smaller ones with less training compute, smaller models are generally preferred due to their increased efficiency during inference.
To train the largest Llama 3 models, a combination of three parallelization techniques was employed: data parallelization, model parallelization, and pipeline parallelization. This approach achieved a remarkable compute utilization of over 400 TFLOPS per GPU when trained on 16K GPUs simultaneously. Training runs were conducted on two custom-built 24K GPU clusters. To maximize GPU uptime, an advanced training stack was developed to automate error detection, handling, and maintenance tasks. Additionally, significant improvements were made to hardware reliability and detection mechanisms for silent data corruption, and scalable storage systems were developed to reduce the overheads of checkpointing and rollback. These collective enhancements resulted in an overall effective training time of over 95%. In summary, these improvements boosted the efficiency of Llama 3 training by approximately threefold compared to Llama 2.
Fine-Tuned
To fully unleash the potential of their pretrained models in chat use cases, they pioneered a novel approach to instruction-tuning. Their post-training methodology combines supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct preference optimization (DPO). The quality of prompts used in SFT and the preference rankings utilized in PPO and DPO significantly influence the performance of aligned models. Substantial improvements in model quality were achieved through meticulous curation of data prompts and multiple rounds of quality assurance on annotations provided by human annotators.
Leveraging preference rankings via PPO and DPO notably enhanced Llama 3’s performance on reasoning and coding tasks. They discovered that when a model encounters a reasoning question it struggles to answer, it sometimes produces the correct reasoning trace; the model knows how to generate the correct answer but lacks the ability to select it. Training on preference rankings allows the model to learn this selection process.
Benchmarks: Llama 3 vs Other Models
The introduction of the new 8B and 70B parameter Llama 3 models represents a significant advancement over Llama 2, setting a new benchmark for large language models at these scales. Through enhancements in both pretraining and post-training methodologies, the pretrained and instruction-fine-tuned models now stand as the leading options in their respective parameter ranges. Refinements in post-training processes have notably diminished false refusal rates, enhanced alignment, and diversified model responses. Moreover, substantial improvements have been observed in critical capabilities such as reasoning, code generation, and instruction comprehension, rendering Llama 3 more adaptable and responsive.
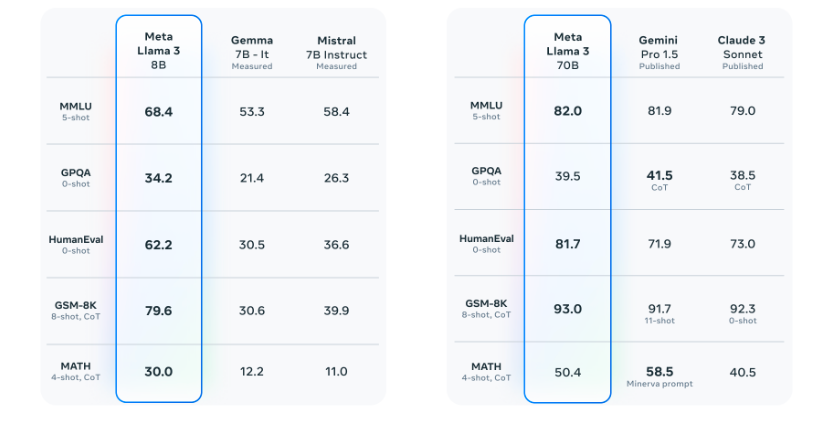
Resource:https://ai.meta.com/blog/meta-llama-3/
In the development of Llama 3, the team focused on assessing model performance on standard benchmarks while also prioritizing optimization for real-world scenarios. To achieve this objective, they created a new high-quality human evaluation set comprising 1,800 prompts covering 12 key use cases, including asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization. To prevent accidental overfitting of their models on this evaluation set, even their own modeling teams do not have access to it. The aggregated results of human evaluations across these categories and prompts, comparing Llama 3 against Claude Sonnet, Mistral Medium, and GPT-3.5, are presented in the chart below.
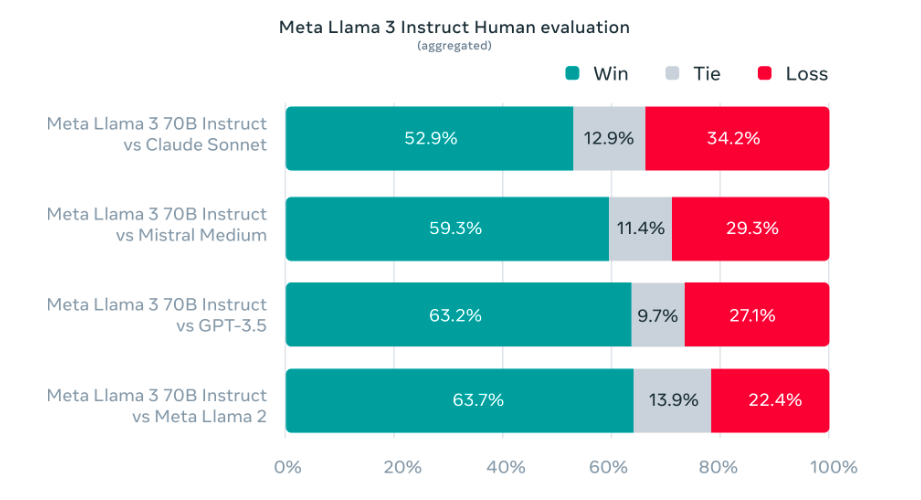
Preference rankings by human annotators based on this evaluation set underscore the robust performance of their 70B instruction-following model when compared to competing models of similar scale in real-world scenarios.
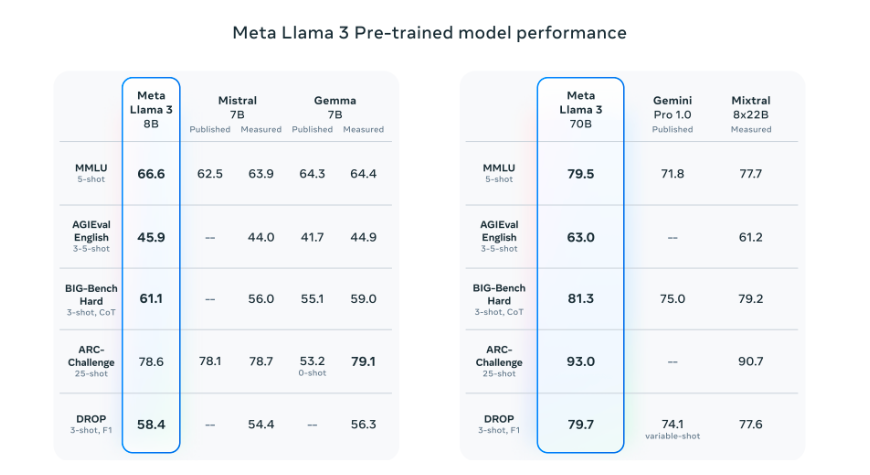
Their pretrained model further solidifies a new state-of-the-art standard for LLM models at those scales.
Getting Started with Llama 3
Getting started with Llama 3 is easy and accessible to developers and researchers. The model can be accessed through Meta AI’s website or via popular AI platforms like GitHub and Hugging Face. To get started, developers can use the provided example command to install and run Llama 3. The code repository contains detailed instructions and documentation for using the model effectively. By following the instructions provided, developers can quickly integrate Llama 3 into their projects and leverage its powerful capabilities through the Hub.
Hardware and Software Requirements for Optimal Use
To optimize the use of Llama 3, it is recommended to have access to powerful hardware, specifically GPUs, for training machine learning algorithms. These GPUs, such as those provided by NVIDIA, accelerate the training and inference processes, enabling faster and more efficient text generation. Additionally, users can leverage cloud platforms like Google Cloud or Azure to access high-performance computing resources for running Llama 3. In terms of software requirements, users need to have the necessary frameworks and tools to integrate Llama 3 into their projects. Meta AI provides detailed instructions and resources to guide users through the setup process and ensure a smooth implementation of Llama 3.
Practical Applications of Llama 3
Llama 3 has a wide range of practical applications across various industries. Its advanced capabilities in text generation and understanding make it a valuable tool for businesses and individuals alike. Llama 3 can enhance business operations by automating repetitive tasks and improving efficiency. Additionally, it can be used in content creation for industries like marketing and creative arts, generating code, scripts, and even poems. The possibilities are endless, and Llama 3 offers a new level of flexibility and creativity in AI applications.
Apply Llama 3 to LLMs
Integrating LLM with Llama 3 opens up new opportunities for developers in the AI community. This integration allows developers to leverage the capabilities of large language models and access a wide range of functionalities for their applications.
Here is a Real-World Examples of Successful Integrations:
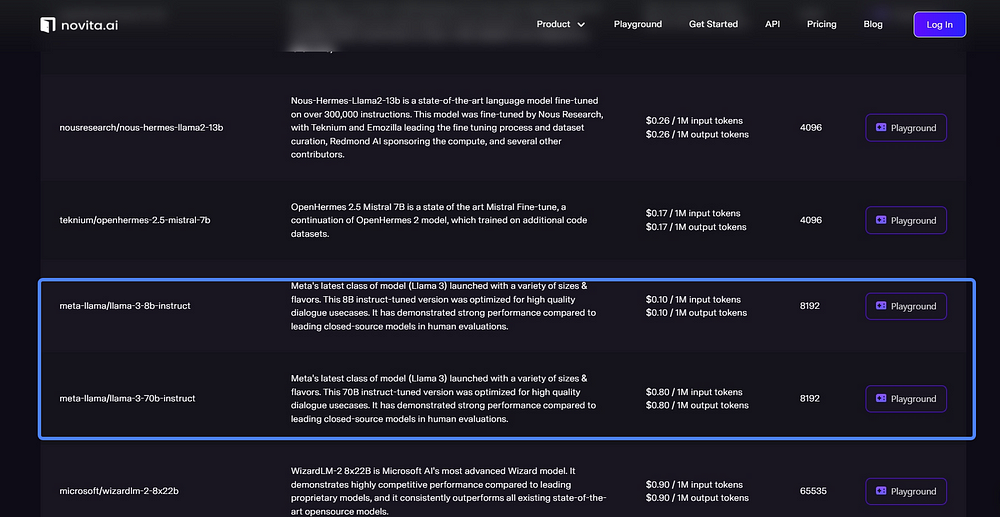
The integration of novita.ai LLM API with Llama 3 brings several benefits for developers. These include improved developer experience, access to reliable and efficient language understanding, and the opportunity to enhance the functionality of their applications.
Creative Uses of Llama 3 in Content Creation
Llama 3 opens up new possibilities in content creation for creative industries such as marketing, advertising, and entertainment. Its advanced text generation capabilities enable it to create engaging and compelling content, including code, scripts, and even poems. Llama 3 can generate unique and personalized content tailored to specific audiences, making it a valuable tool for content creators. Additionally, Llama 3 can be used in language translation, summarization of factual topics, and even generating musical pieces. With its ability to understand and generate human-like text, Llama 3 provides content creators with a new level of creativity and flexibility.
Safeguarding the Future: Security and Ethics
As with any advanced technology, security and ethics are crucial considerations when it comes to Llama 3. Meta AI is committed to ensuring the responsible use of Llama 3 and has implemented measures to safeguard user security and data privacy. Llama Guard 2, Code Shield, and CyberSec Eval 2 are some of the trust and safety tools introduced by Meta AI to address cybersecurity concerns. Furthermore, Meta AI emphasizes the importance of ethical considerations and has provided a responsible use guide to promote the responsible and ethical use of Llama 3.
Addressing Cybersecurity Concerns with Llama 3
Meta AI understands the importance of cybersecurity when it comes to Llama 3 and has taken measures to address these concerns. Llama Guard 2, Code Shield, and CyberSec Eval 2 are advanced security tools developed by Meta AI to protect against potential threats and vulnerabilities. Llama Guard 2 provides robust protection against cyberattacks, ensuring the security and integrity of the model and its outputs. Code Shield protects the codebase of Llama 3, preventing unauthorized access and malicious activities. CyberSec Eval 2 evaluates and assesses the cybersecurity measures in place, ensuring that Llama 3 adheres to the highest security standards. With these various resources in place, including Llama Guard 2, Code Shield, and CyberSec Eval 2, users can have confidence in the security and integrity of Llama 3.
Ethical Considerations and Limitations in Using Llama 3
Ethical considerations are paramount when it comes to the use of advanced AI models like Llama 3. Meta AI acknowledges the ethical implications and limitations of Llama 3 and promotes responsible use through its responsible use guide. The guide provides guidelines and best practices for using Llama 3 in an ethical and responsible manner. It emphasizes the importance of respecting privacy, avoiding biased or discriminatory outputs, and ensuring transparency in the use of AI technologies. By adhering to these ethical considerations and limitations, users can harness the power of Llama 3 while mitigating potential risks and ensuring the responsible use of AI.
What’s next for Llama 3?
The release of the Llama 3 8B and 70B models marks the initial stage of our planned offerings for Llama 3, with much more in store. Excitingly, our largest models exceed 400B parameters, and although they are still undergoing training, our team is enthusiastic about their progress. In the upcoming months, we will unveil multiple models with enhanced capabilities, including multimodality, multilingual conversation abilities, extended context windows, and overall stronger performance. Additionally, upon completion of training, we will publish a comprehensive research paper detailing Llama 3.
As these models continue to train, we wanted to provide a sneak preview of their current progress. It’s important to note that the data presented is based on an early checkpoint of Llama 3 that is still in training, and these capabilities are not yet supported in the models released today.
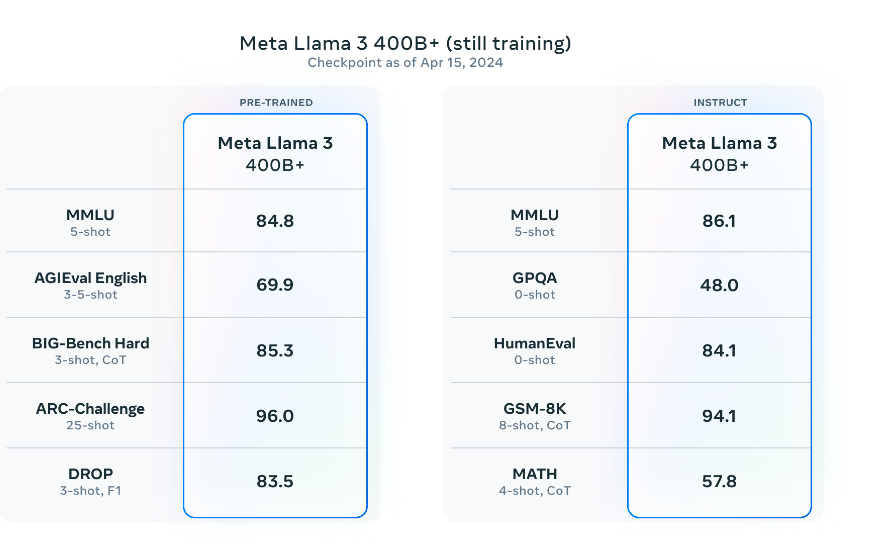
They remain steadfast in their dedication to fostering the ongoing expansion and advancement of an open AI ecosystem for the responsible release of their models. Firmly believing that openness fosters the creation of superior, safer products, accelerates innovation, and promotes a healthier marketplace overall, they are committed to this ethos. Embracing a community-centric strategy with Llama 3, they have initiated the availability of these models on top cloud, hosting, and hardware platforms, with plans for further expansion in the future. This approach benefits both Meta and society at large.
Conclusion
Meta AI’s unveiling of Llama 3 signifies a pivotal moment in the advancement of AI technology, promising to reshape the landscape with its unparalleled capabilities and performance. With a steadfast commitment to responsible innovation and an open-source ethos, Meta AI is poised to revolutionize the field of AI while fostering a collaborative community-driven approach. As Llama 3 continues to evolve and expand its capabilities, it holds the potential to drive transformative change across various industries, offering developers and researchers powerful tools to push the boundaries of what is possible in AI. With its focus on security, ethics, and responsible use, Meta AI ensures that Llama 3 not only delivers exceptional performance but also upholds the highest standards of integrity and user trust, paving the way for a future where AI serves as a force for positive impact in society.
Frequently Asked Questions
Can I Use Llama 3 for Commercial Purposes?
Yes, Llama 3 can be used for commercial purposes. However, it is essential to review and adhere to the Meta Llama 3 Community License Agreement, which outlines the terms and conditions for commercial use.
How Does Llama 3 Handle Data Privacy and User Security?
Meta AI prioritizes data privacy and user security in Llama 3. The company has implemented advanced security measures, including Llama Guard 2 and Code Shield, to protect against cybersecurity threats and ensure the privacy and security of user data.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.