


Key Highlights
Meta LLaMA 3: A powerful, open-source model with advanced NLP capabilities, ideal for research and enterprise tasks due to its flexibility and scalability.
Mistral 7B: A highly efficient, lightweight model that excels in real-time tasks like coding and chatbots, using innovative attention mechanisms for improved performance.
Customization: Both models are open-source. LLaMA offers extensive fine-tuning for specialized tasks, while Mistral emphasizes performance optimization and easy deployment.
Performance & Efficiency: Mistral outperforms larger models in specific areas (e.g., code generation) while being more resource-efficient. LLaMA excels at large-scale NLP tasks with high accuracy.
Scalability: LLaMA is ideal for large enterprises, while Mistral provides a cost-effective, efficient solution for smaller, real-time projects.
API Accessibility: Both the Mistral and LLaMA 3 model APIs are available on Novita AI. Additionally, Novita AI offers the LLaMA 3.1 API with easy-to-use features for seamless integration.
Introduction
Meta’s LLaMA 3 and Mistral are two of the most advanced AI models currently available. Each offers unique features, performance capabilities, and customization options, making them suitable for a wide range of applications. In this article, we’ll provide a comparative analysis of these two models based on their performance, efficiency, scalability, and versatility, helping you choose the right solution for your AI needs.
Understanding Meta Llama 3
Meta Llama 3 is a state-of-the-art language model developed by Meta Platforms, Inc. It represents the latest advancements in natural language processing (NLP) and artificial intelligence (AI). Designed to enhance various applications, Meta Llama is known for its impressive capabilities in text generation, comprehension, and conversational AI.
How Does Llama Work?
Llama, built on a transformer-based architecture, excels in handling complex tasks like text generation and NLP. The transformer model breaks input data into tokens, using self-attention mechanisms to capture word relationships and generate coherent responses across different prompts.
One of Llama’s key strengths is its flexibility, particularly in its ability to be fine-tuned for specific tasks. Developers can start with the pre-trained Llama model and customize it using smaller, domain-specific datasets. This makes Llama a highly adaptable solution for businesses seeking AI models tailored to their unique needs.
Key Features of Llama
Open-Source Access: Llama’s open-source nature allows developers and researchers to freely access, modify, and deploy the model for various applications without licensing restrictions.
Customizable for Specific Tasks: Llama is adaptable for fine-tuning on domain-specific datasets, allowing customization for specific needs, enhancing relevance and accuracy for specialized tasks.
State-of-the-Art Performance: Llama excels in producing coherent and contextually appropriate text for advanced NLP tasks like question answering and conversational AI.
Scalability: Llama can scale easily for small-scale applications or large enterprises, making it a flexible solution for different industries.
These qualities make Llama a great option for research and business use. Its ability to adapt and perform well creates new opportunities in the field of language models and text generation.
Exploring Mistral
Mistral is a new, efficient AI model designed for developers and businesses seeking open, flexible solutions. Its models, like Mistral Large and Mistral Nemo, are available under Apache 2.0 licenses, ensuring broad accessibility.
The Mistral 7B model, with 7.3 billion parameters, outperforms larger models like LLaMA2–13B while using less computational power. It can be deployed on cloud platforms, serverless APIs, or on-premise, offering great flexibility.
How Does Mistral Work?
Mistral’s unique transformer architecture is designed for efficiency and flexibility. Using a “windowed attention” mechanism, it focuses on smaller text chunks, reducing computation while maintaining high performance. Ideal for code generation or document summarization.
By combining windowed attention with a streamlined transformer design, Mistral delivers strong performance with low resource usage. The Mistral 7B model enhances inference speed using Grouped Query Attention (GQA) and Sliding Window Attention (SWA), allowing it to efficiently handle long sequences while keeping costs down.
Key Features of Mistral
Efficient Transformer Architecture: Mistral 7B is built on an optimized transformer architecture, designed for efficiency, making it ideal for a variety of applications.
Window Attention Mechanism: Rather than processing all tokens simultaneously, Mistral uses windowed attention to focus on smaller sections of text, reducing computational demand while maintaining strong performance.
Exceptional Performance: Mistral 7B outperforms larger models in tasks like code generation, mathematics, and reasoning, offering superior results with lower resource consumption.
Grouped Query Attention (GQA): GQA accelerates inference in Mistral, allowing for larger batch sizes and faster processing, making it ideal for real-time applications.
Sliding Window Attention (SWA): SWA enables Mistral to efficiently handle long sequences, overcoming the limitations of traditional language models.
Customizability: Mistral’s architecture is highly flexible, making it easy to fine-tune for specific tasks, from chatbots to industry-specific applications.
Open Source: Released under the Apache 2.0 license, Mistral is open for unrestricted use, modification, and redistribution, promoting innovation and collaboration.
With this mix of versatility, affordability, and good performance, Mistral changes the game in the world of LLMs. It helps more people access advanced AI.
Mistral VS Llama 3: In-depth Comparison
Both Llama and Mistral are great in AI language models. However, they have different strengths for different needs. Knowing these differences is important for picking the right model for you.
In this comparison, we’ll look at important areas where these models are different. This includes how well they perform, how custom they can be, and how efficient they are with resources. This detailed look will help you feel sure when choosing between these two strong AI options.
Performance
Mistral and Llama 3 both excel in performance, but they are optimized for different use cases. Mistral 7B outperforms larger models, especially in tasks like code generation, mathematical reasoning, and text summarization, thanks to its efficient architecture and innovative attention mechanisms like Grouped Query Attention (GQA).
Llama 3, on the other hand, is a robust performer in a wide range of NLP tasks, with larger models (e.g., Llama 3–70B) providing high accuracy across diverse text generation and comprehension tasks. However, Mistral is typically faster and requires less computational overhead for similar performance.
Customization and Flexibility
LLaMA AI is highly customizable thanks to its open-source nature, allowing developers to fine-tune it for specific needs. Its flexibility makes it suitable for both research and enterprise applications, adapting easily to various use cases.
Mistral, while offering some customization options, focuses more on performance optimization and efficiency. Its models can be fine-tuned, but the real strength lies in its portability, with the ability to deploy across public clouds, serverless APIs, or on-premise, offering businesses greater deployment flexibility.
Scalability
LLaMA is highly scalable, especially with larger models like LLaMA 70B, making it ideal for enterprise-level applications. It can easily scale up for large projects or down for smaller tasks, offering great versatility for various business needs.
Mistral models, on the other hand, are designed for cost efficiency, efficiency, and scalability in real-time and mid-sized applications. The Mistral 7B delivers strong performance at a smaller size, handling tasks that would typically require larger models, which makes it a more cost-effective choice. However, for extremely large-scale deployments, LLaMA may provide better scalability.
Resource Efficiency
Mistral 7B is highly resource-efficient, delivering strong performance despite its smaller size. It outperforms larger models like LLaMA2–13B and LLaMA1–34B in several benchmarks, making it an excellent choice for businesses seeking powerful AI without the need for heavy computational resources.
While LLaMA is more efficient than traditional models like GPT-3, larger versions like LLaMA 70B still demand significant computational power. To fully harness LLaMA’s capabilities, businesses will need to invest in robust hardware or cloud infrastructure.
Applications
LLaMA’s versatility makes it a strong fit for a variety of use cases, including natural language processing, content creation, code generation, and chatbot development. Its scalability allows it to handle projects of any size, from small applications to large-scale enterprise solutions, such as:
Enterprise-level applications
Custom AI tools
Customer service automation
Content creation (for more insights, explore top AI writing tools)
Mistral, on the other hand, excels in real-time applications that demand fast inference and high performance. With its efficient design and speed-optimized architecture, Mistral is ideal for tasks like coding, chatbot deployment, and instructional AI. Its smaller size allows for easy deployment on standard hardware without requiring extensive resources.
If you’d like to learn more about Mistral vs. LLaMA 3, check out the video ‘LLaMA 3 vs. Mistral Test Blowout’.
Llama or Mistral: Which Model Best Fits Your Needs?
Choosing between Mistral and LLaMA AI ultimately depends on your specific needs and priorities:
Mistral is ideal if you need efficiency, speed, and low resource usage. The Mistral 7B model delivers strong performance for real-time applications and smaller to mid-scale projects. Its portability makes it easy to deploy on standard infrastructure, perfect for businesses with limited resources.
LLaMA excels in scalability and customizability, making it great for complex and large-scale projects. As an open-source model, it can be fine-tuned for a wide range of tasks. With sizes from LLaMA 7B to LLaMA 70B, it’s ideal for research and enterprise applications.
Making the Right Choice:
If your focus is on speed, efficiency, and cost-effective deployment, Mistral offers a compelling solution. Its real-time performance and lightweight architecture make it ideal for businesses that need high-performance AI without investing in heavy infrastructure.
If you need a more scalable, customizable, and versatile AI framework, LLaMA is the better choice. Its ability to handle a wide range of tasks with different model sizes and fine-tuning options makes it well-suited for more complex or large-scale applications.
Ultimately, the choice between Mistral and LLaMA depends on your specific project requirements — whether you need efficiency and speed for real-time applications or scalability and customizability for more extensive use cases. Mistral prioritizes portability and performance in resource-constrained environments, while LLaMA excels in handling large, complex tasks and offering high levels of customization.
No matter which model you choose, both offer powerful capabilities that can be seamlessly integrated into your AI projects. To streamline your development process, consider using the Mistral and LLaMA 3 APIs available on Novita AI — the platform that provides the tools to meet all your AI needs.
Meet all your needs: Use the Mistral and Llama 3 APIs on Novita AI.
Choosing between two great AI models can be hard. But what if you didn’t have to pick? With Novita AI, you get both Mistral AI and Llama 3 in one easy platform.
Novita AI simplifies your work by providing Mistral and Llama 3 APIs. This lets you use the best features of each model without the trouble of handling different setups. If you need Mistral for fast code generation or the flexibility of Llama for various NLP tasks, particularly in general knowledge areas, Novita AI lets you switch between them easily. This way, you can make the most of your AI options.
Step-by-Step Guide to Novita LLM API
- Step 1: Create an account or log in to Novita AI

Step 2: Go to the Dashboard tab on Novita AI to obtain your LLM API key. You can also choose to generate a new key if needed.
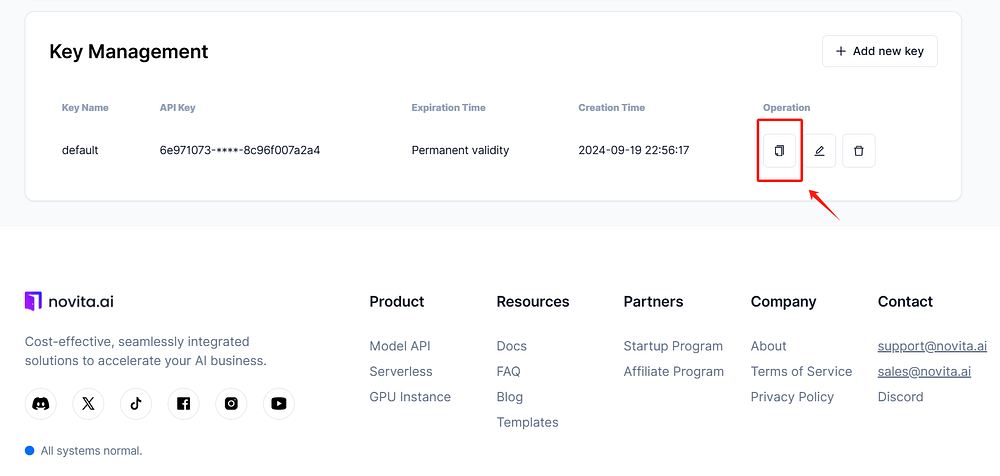
Step 3: Visit the Manage Keys page and click “Copy” to quickly retrieve your key.
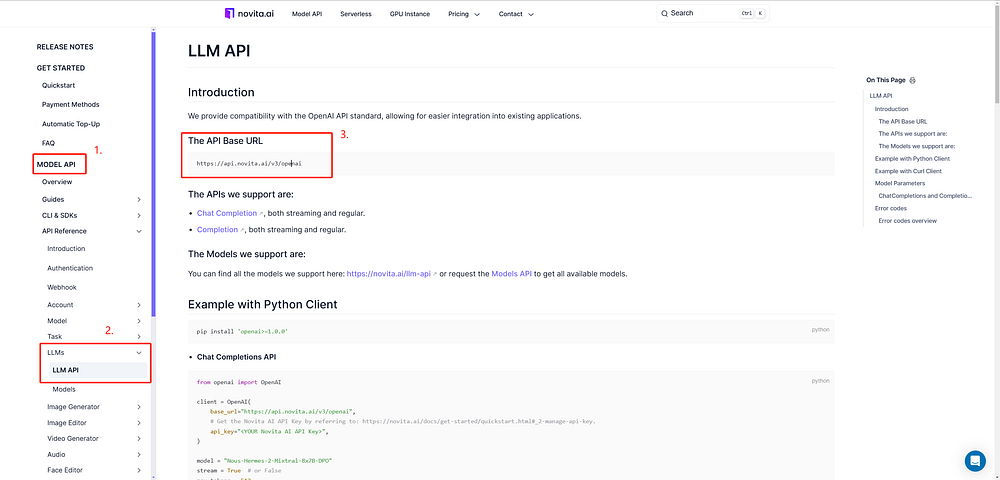
- Step 4: Access the LLM API documentation: Click on “Docs” in the navigation bar, go to “Model API,” and locate the LLM API section to view the API Base URL.

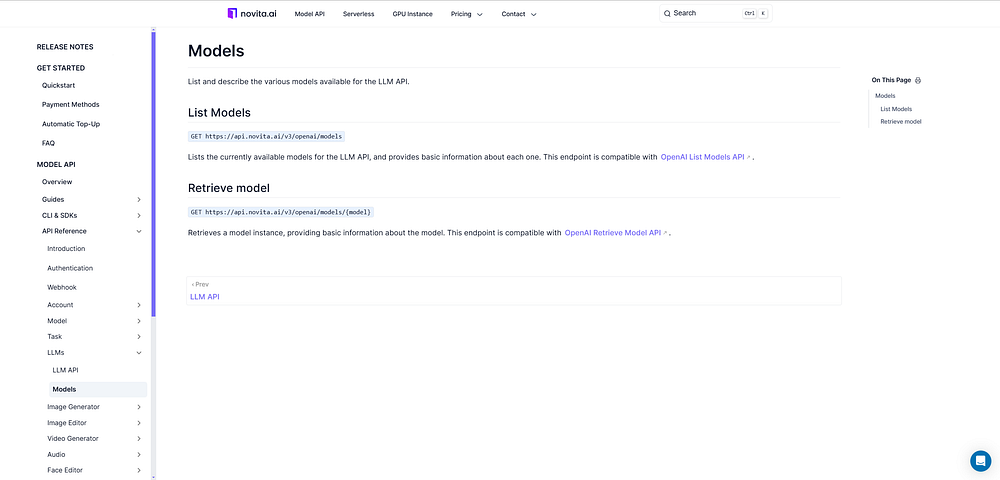
- Step 5: Select the model that suits you best.In addition to the Mistral and LLaMA 3 models, we offer many others. To view the complete list of available models, visit the Novita AI LLM Models List.
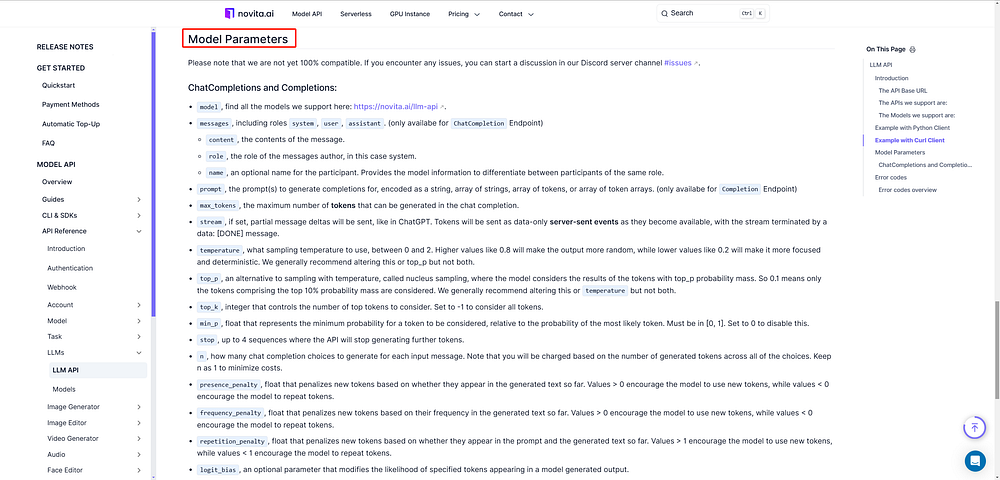
- Step 6: Explore the supported parameters for our models. Novita AI models offer parameters like
prompt,max_tokens,presence_penalty, and more for customization.
- Step 7: Install the necessary libraries and set up your API. Below is a quick example using the Python client.
pip install 'openai>=1.0.0'from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://docs/get-started/quickstart.html#_2-manage-api-key
api_key="<YOUR Novita AI API Key>",
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512
completion_res = client.completions.create(
model=model,
prompt="A chat between a curious user and an artificial intelligence assistant.\nYou are a cooking assistant.\nBe edgy in your cooking ideas.\nUSER: How do I make pasta?\nASSISTANT: First, boil water. Then, add pasta to the boiling water. Cook for 8-10 minutes or until al dente. Drain and serve!\nUSER: How do I make it better?\nASSISTANT:",
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in completion_res:
print(chunk.choices[0].text or "", end="")
else:
print(completion_res.choices[0].text)
How to use the Llama 3 and Mistral demo on Novita AI?
Before calling the LLaMA 3 and Mistral APIs, you can test the models on Novita AI’s LLM demo. This will help you better understand the differences between LLaMA 3 and Mistral before making your API calls.
- Step 1: Access the demo: Go to the “Model API” tab and choose “LLM API” to begin exploring the LLaMA 3 and Mistral models.
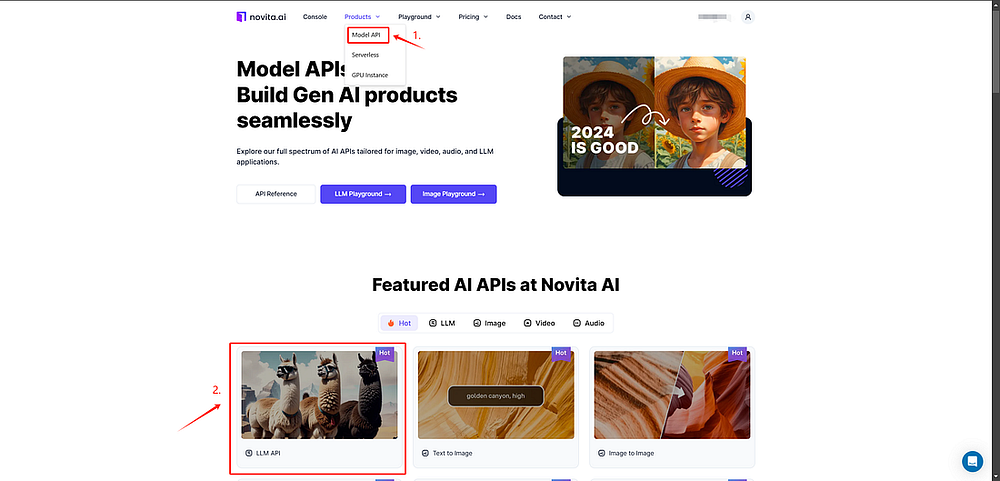
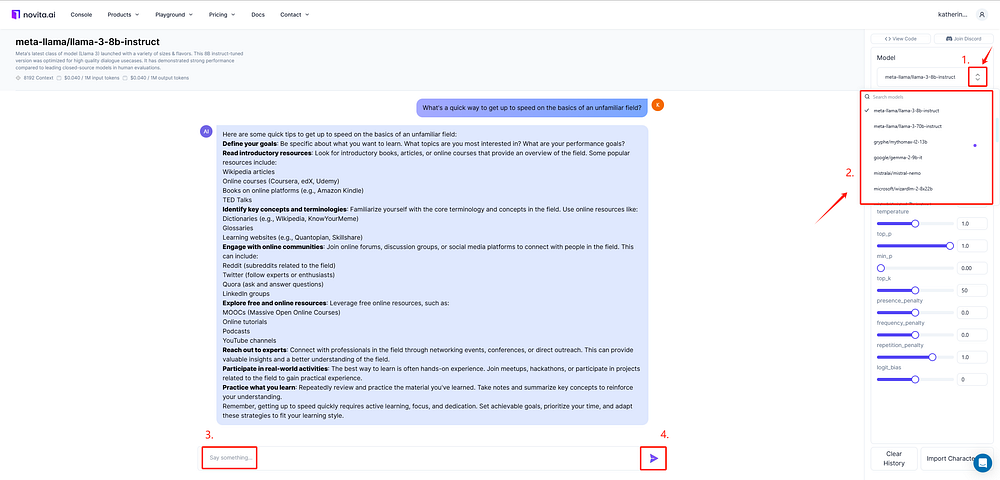
- Step 2: Select the appropriate model, enter your prompt in the designated field, and get the results.
Here’s what we offer for Llama 3 and mistral:
Ready to explore the capabilities of LLaMA 3 and Mistral? Get started now with Novita AI LLM APIs to enhance your AI projects with powerful, efficient, and customizable language models. Start building today!
Conclusion
Both LLaMA 3 and Mistral provide powerful AI capabilities, but their suitability depends on your specific requirements. If you need a customizable, scalable model for large-scale NLP tasks, LLaMA 3 is your ideal choice. On the other hand, if efficiency and fast real-time performance with minimal resource use are more critical, Mistral is the best fit. Whichever you choose, both models can be easily accessed and integrated via Novita AI’s LLM APIs.
Frequently Asked Questions
Mistral 123B vs LLAMA-3 405B, Thoughts?
Mistral 123B excels in model efficiency and response speed, while LLaMA-3 405B stands out for its ability to handle complex tasks and generate high-quality outputs.
Is Mistral better than ChatGPT?
Le Chat, an AI chatbot by Mistral AI, shows promise but lags behind ChatGPT in creativity and programming skills.
What is the difference between Mistral and Mistral NeMo?
Mistral NeMo is a more compact 12 billion parameter model that still offers impressive capabilities: 12 billion parameters.
Is Mistral trained from Llama?
The Mistral Medium is post-trained from Llama, likely due to urgency on having an API that’s close to GPT-4 quality, for early customers.
Why is Mistral so important?
It helps keep the vines well-ventilated and dry after rainfall, acting like a natural antiseptic that wards off diseases by preventing rot from settling in.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.