


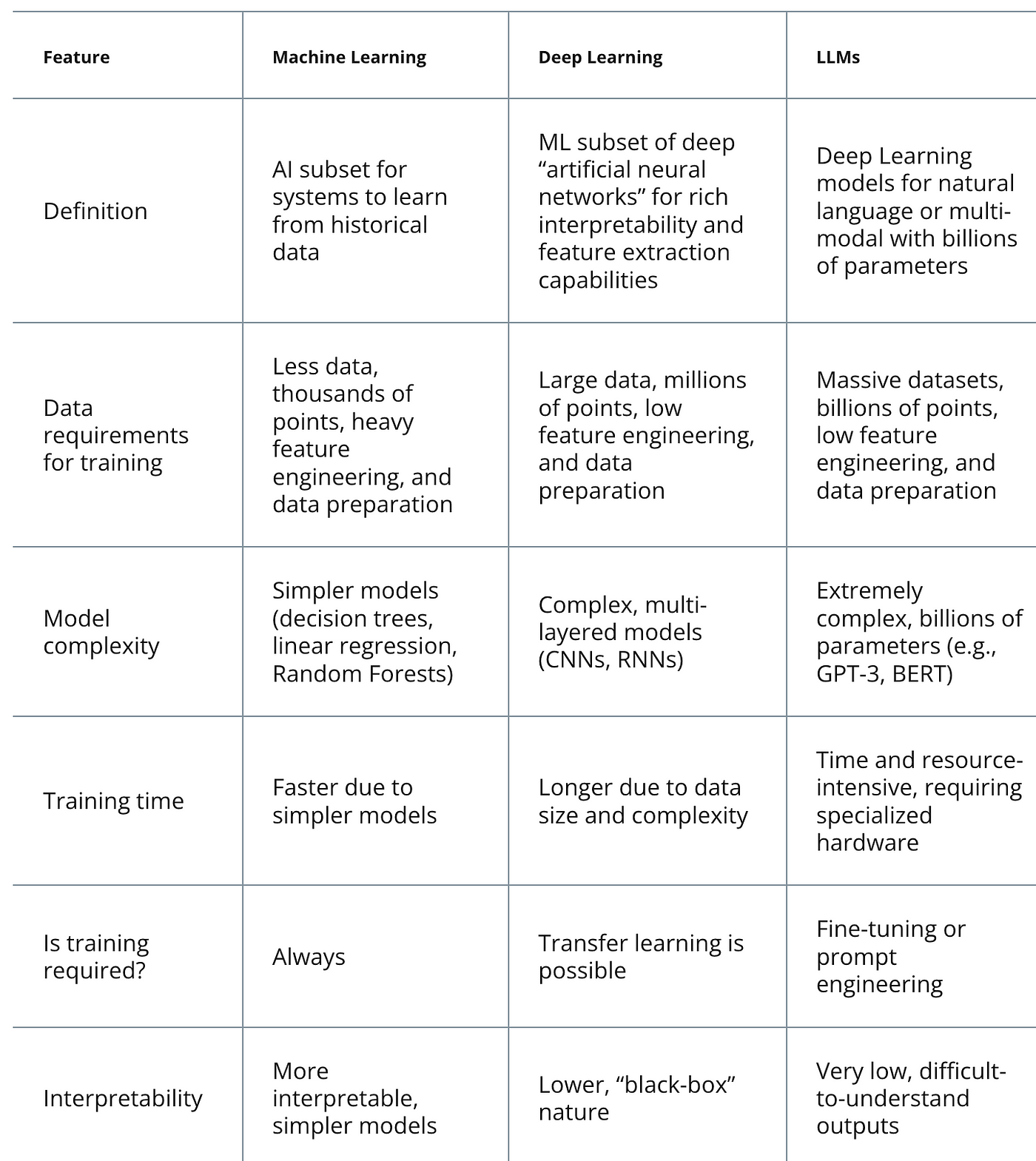
ML vs LLM: What is the difference between Machine Learning and Large Language Model


Introduction
Apart from the prevalent discourse on integrating LLMs into business practices, a less publicized debate is emerging regarding the comparison between traditional Machine Learning (ML) models and Large Language Models (LLMs). The question arises: Are conventional ML models becoming obsolete, with LLMs poised to dominate the AI landscape? Does novelty inherently equate to superiority?
This article aims to dissect the ML vs. LLM discourse, exploring their disparities, functionalities, and instances where one may outperform the other in various AI applications.
Drawing a line between ML and LLM
Initially, it’s essential to recognize that Large Language Models (LLMs) are a subset of Machine Learning (ML). Machine Learning encompasses a broad array of algorithms and models, ranging from basic ones like Naive Bayes to more complex ones like Neural Networks. LLMs, a recent breakthrough, owe their existence to concepts such as Neural Networks and back-propagation for training, which have revolutionized fields like computer vision, natural language processing (NLP), and reinforcement learning. However, the transformative potential of Neural Networks wasn’t fully realized until about a decade ago, primarily due to limitations in data storage and computational power, which were overcome with the widespread adoption of GPUs and affordable data storage and collection methods.
Understanding Machine Learnling
Traditional ML models have long relied on feature extraction, a process crucial for various applications across industries like finance and healthcare. Techniques such as Support Vector Machines and Decision Trees, as well as shallow Neural Networks, which are foundational to LLMs, relied heavily on the quality of feature engineering performed on available data. However, this approach had limitations due to the finite capacity of humans to devise complex mathematical transformations. Deep Neural Networks, particularly those employing Transformer and CNN architectures, represent a significant leap forward by automating and enhancing feature extraction. These models leverage self-supervised learning techniques to exploit vast amounts of unstructured data, reducing the need for extensive preprocessing. While Deep Learning solutions excel in tasks like recommender systems and search, they may not always be suitable for tasks requiring learning-to-rank techniques, where traditional ML solutions like Boosting Trees may be more appropriate.
Understanding NLP(Natural Language Processing)
In the domain of NLP, traditional text-processing techniques like TF-IDF and Bag of Words were instrumental for vectorizing text before the rise of models such as Word2Vec and FastText. Before models like BERT emerged, a considerable portion of NLP efforts focused on perfecting preprocessing steps. Transformers, starting with BERT, paved the way for LLMs, which are trained on vast amounts of text data from the internet. These models excel in complex linguistic tasks like translation, question-answering, and summarization, owing to their extensive training data and large parameter sizes.
If you have interests in the difference between NLP and LLM, you can check our blog: NLP vs LLM: Key Differences and Synergies
The distinction between ML and LLMs depends on the specific requirements of the application. LLMs are often preferable for tasks demanding nuanced language understanding or Generative AI, like chatbots or text summarization, due to their advanced capabilities. However, traditional ML shines in scenarios where interpretability and computational efficiency are crucial, such as structured data analysis or resource-constrained environments like edge devices.
In certain areas like sentiment analysis or recommendation systems, both ML and LLMs may offer viable solutions, each with unique advantages. These methods can be complementary rather than competitive, depending on the specific use case. The following section will delve into implementation details and considerations for each technique, aiding in the decision-making process for various use cases.
The decision matrix for ML vs. LLM
LLMs excel in generative tasks demanding comprehensive language comprehension, whereas traditional ML retains effectiveness in discriminative tasks owing to its efficiency and lower resource requirements. For example, ML may be favored for sentiment analysis or customer churn prediction, whereas LLMs are preferred for intricate tasks like code generation or text completion.
ML vs. DL vs. LLM demo pipelines
Let’s delve into a scenario where we aim to construct a sentiment analysis model for evaluating the positivity or negativity of reviews on an e-commerce platform.
We’ll examine three distinct methodologies: employing Machine Learning utilizing XGBoost, leveraging Deep Learning via TensorFlow, and conducting sentiment analysis prediction utilizing a Large Language Model sourced from OpenAI.
ML with XGBoost
To begin, I’ll delve into the utilization of XGBoost, a robust and efficient Machine Learning algorithm, for sentiment analysis. This demonstration will highlight the steps involved in extracting features from textual data, training the model, and evaluating its performance, underscoring the capability of XGBoost in effectively handling structured data.

This code excerpt illustrates the implementation of a Machine Learning pipeline designed for sentiment analysis, utilizing XGBoost, a renowned gradient boosting framework, in conjunction with TF-IDF for text vectorization. The fundamental concept involves converting textual data into numerical vectors using TF-IDF, a technique that captures the significance of words within a corpus, followed by the application of XGBoost, an efficient and potent algorithm based on Boosting Trees, for a binary classification task. This pipeline proves particularly effective for structured datasets and is ideal for scenarios prioritizing interpretability and computational efficiency. However, it’s important to note that in this scenario, we assume the text data supplied to the pipeline is in pristine condition, which is often not the case. Typically, preceding steps involve text processing tasks such as stop-word removal and text normalization.
DL with TensorFlow:
In the following example, I’ll showcase a Deep Learning approach employing TensorFlow. Here, we construct a straightforward (shallow) neural network to handle text data, aiming to illustrate how Deep Learning can discern intricate patterns in language by traversing layers of neural networks. Below is an illustration utilizing TensorFlow with Keras:

Transitioning from the earlier demonstration of a conventional Machine Learning method for sentiment analysis, this code snippet shifts focus to a Deep Learning approach utilizing TensorFlow, a robust framework for constructing neural network-based models. At the heart of this Deep Learning illustration lies the embedding layer, a concept notably popularized by Word2Vec. This layer translates words into dense vectors within a high-dimensional space, capturing semantic relationships in a manner beyond simple numerical vectorization. In contrast to the previous TF-IDF and XGBoost approach, this deep learning model learns word representations in context, enabling it to grasp subtleties in language usage. The model employs a basic neural network architecture comprising an embedding layer, a pooling layer for dimensionality reduction, and a dense layer for classification.
It’s worth noting that, for simplicity, the implemented Neural Network features only one hidden layer. To fully leverage the feature extraction capabilities of Deep Neural Networks (DNNs), a neural network with greater depth and complexity would be necessary. This methodology proves potent for extensive, intricate datasets where capturing nuanced linguistic patterns is paramount. It serves as a prime example of how Deep Learning can streamline and enhance feature extraction, a task traditionally demanding extensive manual intervention and domain expertise.
LLM with GPT-3
Finally, I explore an example employing a Large Language Model, specifically GPT-3, showcasing how these sophisticated models, pre-trained on extensive datasets, can be utilized for sentiment analysis with minimal configuration, albeit relying on external APIs and resources. Below is an illustration utilizing OpenAI’s GPT-3 API for sentiment analysis:

This final code snippet presents an alternative approach to sentiment analysis by leveraging OpenAI’s GPT-3 (Davinci model), an advanced Large Language Model (LLM).
Here, the intricacies of model training and feature extraction are abstracted, as you’re essentially taking a shortcut by utilizing a pre-trained model. Unlike the previous examples where models were trained on specific datasets tailored to the task, GPT-3 has undergone training on vast and diverse datasets, equipping it with the ability to comprehend and generate human-like text.
The primary advantage of this approach lies in its simplicity and versatility. With just a few lines of code and some prompt engineering, you can harness the capabilities of GPT models to execute a wide array of tasks, including sentiment analysis, without the need for extensive data preprocessing or model training. This snippet communicates text to the GPT-3 API and retrieves a sentiment assessment, showcasing how LLMs can be readily deployed for immediate use. It underscores the strides made in natural language processing, where the complexity of language comprehension is embedded within the pre-trained model, making it highly potent and user-friendly across various applications.
However, while this solution is easier to implement and potentially more robust, it obscures the intricate training process involved in developing a Large Language Model. This aspect may prompt technical and financial considerations, which we’ll delve into further next.
Diving into technical considerations
Exploring the technical terrain of Large Language Models involves navigating both technical debt and cost considerations. While these models streamline deployment and alleviate complexities, as illustrated in the examples above, they also entail financial implications. This transition from technical to financial challenges underscores the need for a closer examination of the trade-offs between technical efficiency and the tangible costs linked with deploying and upholding LLMs.
Technical debt and cost
Reflecting on the earlier examples, it’s evident that while LLMs such as GPT-4 or Llambda offer streamlined processing and user-friendliness, they also pose challenges in terms of costs. These models, adept at comprehending and responding to various prompts, notably simplify the deployment process and alleviate the complexities typically linked with model development and upkeep. This stands in sharp contrast to ML methods like XGBoost, which demand more hands-on involvement in feature engineering and model optimization.

When considering applications of LLMs, they can be regarded as a means to transform the complexities and technical hurdles associated with constructing machine learning and deep learning pipelines into a financial cost. This is because transformers, the underlying architecture of these models, handle the intricate task of feature extraction, which traditionally demands substantial computational resources and expertise. However, this convenience comes with a trade-off in the form of heightened dependence on powerful graphics processing units (GPUs). These GPUs represent either a direct expense if one hosts their own LLM, such as Llambda, or this cost is integrated into the service fee when utilizing a managed service, as with OpenAI models. Essentially, the burden of technical complexity is transitioned into a financial one, rendering the technology accessible but at a price.
Latency and task nature
In user-facing applications, the speed at which AI models can process and respond to inputs, known as latency, holds paramount importance.

Traditional ML models, renowned for their rapid processing capabilities, are ideal for high-speed, real-time applications like executing financial trading algorithms, providing recommendations, or managing emergency response systems where split-second decisions are critical.
For years, academia and industry have invested significant efforts in optimizing and scaling the computational costs associated with prediction and training of ML models.
However, the landscape changes when dealing with LLMs. Take, for example, a virtual assistant in a customer support application. While immediate responses remain essential, the comprehensive language comprehension of LLMs can markedly enhance the quality and depth of interactions, justifying a slight delay in responses. This nuanced trade-off is also evident in content generation tasks, where the richness and coherence of text or images generated by LLMs can outweigh the necessity for instantaneous results typically seen in other applications.
Essentially, the choice between traditional ML models and LLMs requires a meticulous evaluation of the specific nature and urgency of the tasks at hand. The balance between latency and language understanding emerges as a critical factor in determining the optimal solution for a given technical context, underscoring the necessity for tailored approaches and recognition that diverse applications necessitate distinct considerations.
Nevertheless, ongoing efforts are underway to optimize the computational resources required by these LLMs to deliver faster responses on a larger scale.
Conclusion
When considering ML versus LLMs, it’s essential to grasp their unique strengths and weaknesses. The decision ultimately depends on specific application requirements and constraints, such as cost, latency, and the nature of the task. However, two key considerations should always be at the forefront when assessing your options.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.