


Step-by-Step Tutorial on Integrating Retrieval-Augmented Generation (RAG) with Large Language Models


Introduction
Integrating retrieval-augmented generation (RAG) with large language models (LLMs) has revolutionized the field of question answering. With RAG, LLMs can go beyond simple extractive QA and generate human-like responses to user queries by combining retrieval and generation techniques. This allows LLMs to incorporate domain-specific data, such as internal documents or knowledge bases, that were not available during their initial training.
The concept of RAG, sometimes referred to as generative question answering, has gained significant popularity due to its ability to reduce the time spent searching for answers in search results. Instead of relying solely on existing documents, RAG-enabled LLMs can precisely find the most relevant documents and use them to generate accurate and informative answers.
In this step-by-step tutorial, we will explore the key components of RAG systems, understand how to implement RAG with LLMs, and discuss the process of fine-tuning RAG for optimal performance. Additionally, we will explore the practical applications of RAG in business and research, as well as the common pitfalls to be aware of during implementation.
By the end of this tutorial, you will have a comprehensive understanding of RAG and be equipped with the knowledge to integrate this powerful technology into your own question answering systems.
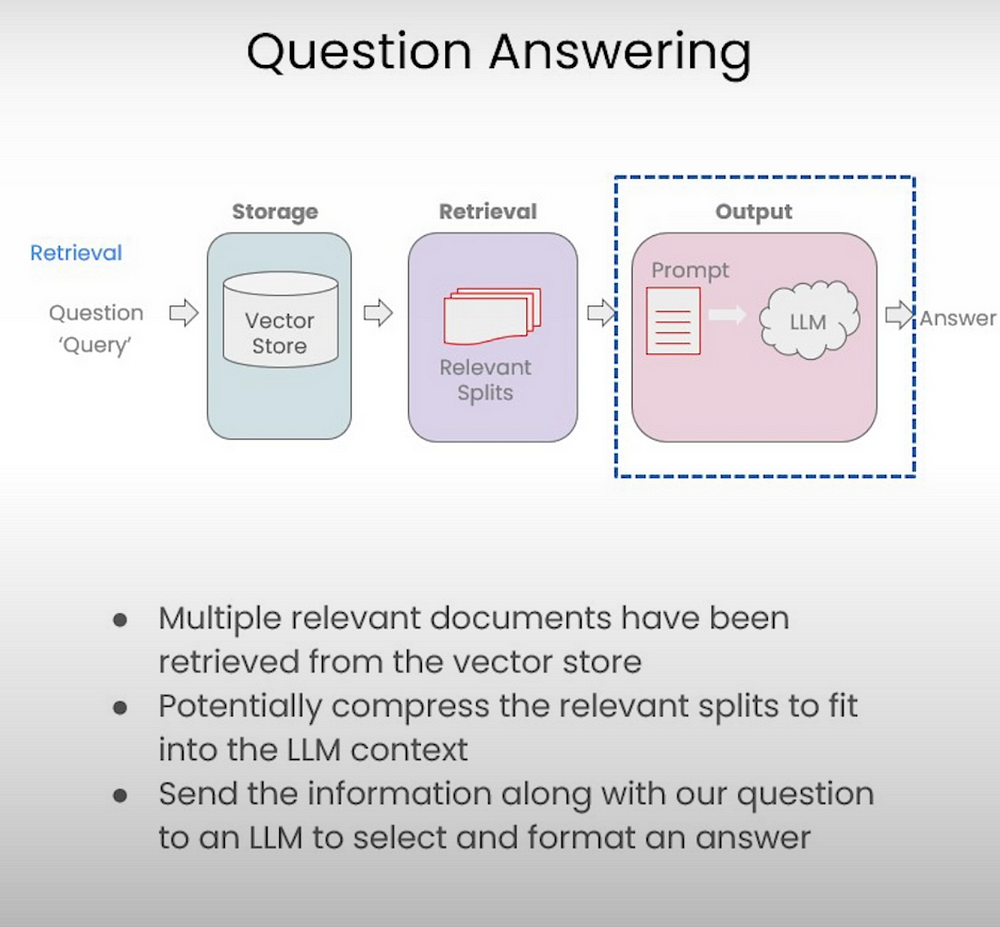
What is RAG(Retrieval-Augmented Generation)
RAG, short for Retrieval-Augmented Generation, combines retrieval and generation techniques to enhance question answering systems. This innovative approach leverages the power of generative AI alongside a retrieval system for providing more accurate and comprehensive responses. By integrating RAG into large language models, the system can effectively sift through vast amounts of data to offer the most relevant information. This fusion bridges the gap between generative question answering and document retrieval, resulting in advanced capabilities for natural language understanding and response generation within AI systems.
Document Retrieval
This step involves identifying and retrieving the most relevant documents or passages from a large collection based on the user’s question. This can be done using various techniques such as keyword matching, vector space models, or more sophisticated methods like embedding-based retrieval, where documents and questions are transformed into vectors in a high-dimensional space.
Question Answering
Once the relevant documents are retrieved, the LLM analyzes the content to extract or generate an answer to the user’s question. This could involve simple extraction of facts, or more complex reasoning based on the information found in the documents.
The Technical Backbone of RAG Using Large Language Model
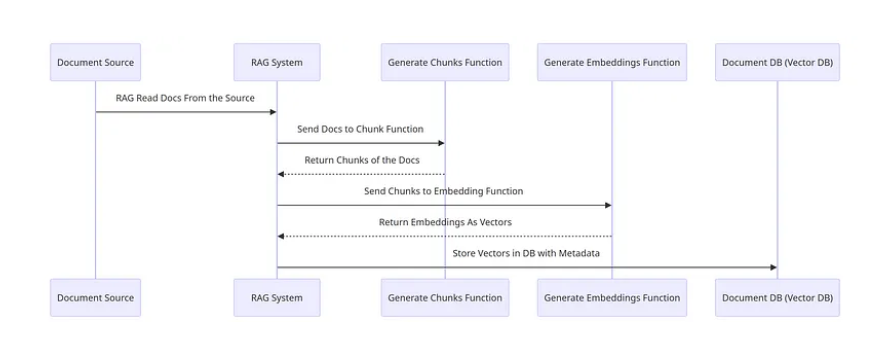
Document Processing and Preparation
The process begins with loading and interpreting documents in various formats such as text files, PDFs, or database entries. These documents are divided into smaller sections like paragraphs, sentences, or even finer segments. Utilizing NLP tools like NLTK simplifies this step significantly, handling complexities such as newlines and special characters, thereby allowing engineers to concentrate on more sophisticated tasks.
Text Embedding and Indexing
Each section of text is transformed from characters to numerical vectors through text embedding, using models like the Universal Sentence Encoder, DRAGON+, Instructor, or large language models. These embeddings, which encapsulate the semantic significance of the text, are then stored in a vector database to create a searchable index. This index aids in the efficient retrieval of information. Potential tools for this purpose include:
NumPy: Simple but effective for linear searches across document collections.
Faiss: Known for its ease of use and variety of indexing algorithms. However, it requires manual result filtering and does not support sharding or replication by default.
Elasticsearch/OpenSearch: Though complex to deploy, these handle not just vector retrieval but also filtering, sharding, and replication.
Vector databases like Pinecone or Chroma.
Query Processing and Context Retrieval
Upon receiving a query, it is embedded using a model aligned with the indexed data, typically the same model used for text embedding unless an asymmetric dual encoder like DRAGON+ is used, requiring a different model from the pair. The system then identifies the most relevant text sections through similarity search metrics such as cosine similarity, providing a context for formulating an answer.
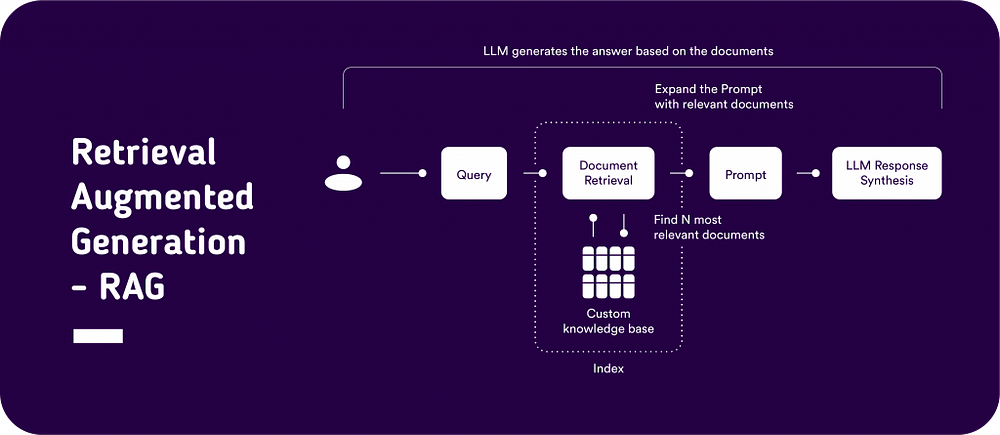
Answer Generation
The LLM functions as a generative model, utilizing the contexts retrieved in addition to the posed question to craft a response. It computes the conditional probability of word sequences to produce an answer that is not only accurate in context but also insightful.
How to Integrate RAG with Large Language Models
Implementing Retrieval-Augmented Generation (RAG) with large language models (LLMs) involves several steps, including dataset preparation and integration into the LLM setup. This process enables the LLM to leverage retrieval techniques and generate more accurate and contextually relevant answers.
Preparing Your Dataset
The first step in implementing Retrieval-Augmented Generation (RAG) with large language models (LLMs) is to prepare your dataset. The dataset plays a crucial role in training and fine-tuning the model to generate accurate and contextually relevant answers.
When preparing your dataset for RAG, consider the following:
Collecting relevant documents: Identify and gather the documents that contain the information you want the RAG system to leverage during question answering.
Preprocessing unstructured data: Clean and preprocess the text data to remove noise and ensure consistency.
Structuring the dataset: Organize the dataset to align with the input and output requirements of the RAG system. This typically involves pairing the input query or prompt with the corresponding answer or relevant documents.
Training data selection: Select a subset of the dataset to use as training data for fine-tuning the LLM. This subset should represent the variety of examples and query types that the RAG system will encounter.
Additionally, consider representing the documents in vector format for efficient retrieval. Vector representations capture the semantic meaning of the documents, enabling the retrieval component to identify relevant documents more accurately.
Integrating RAG into Your LLM Setup
After preparing your dataset for Retrieval-Augmented Generation (RAG), the next step is to integrate RAG into your large language model (LLM) setup. This integration enables the LLM to leverage retrieval techniques and generate more accurate and contextually relevant answers.
To integrate RAG into your LLM setup, follow these steps:
Choose a suitable large language model architecture: Select an LLM that aligns with your requirements and fine-tune it on your prepared dataset.
Incorporate the generative models: Configure the pipeline to include the generative models that will be responsible for generating the answers based on the input query and retrieved documents.
Include the retrieval component: Integrate the retrieval component into the pipeline to enable document retrieval. This component determines the most relevant documents to incorporate into the generative models.
Configure probability estimation: Adjust the probability estimation parameters to control the balance between the retrieval and generation components. This ensures that the generated answers are based on both the input query and the retrieved documents.
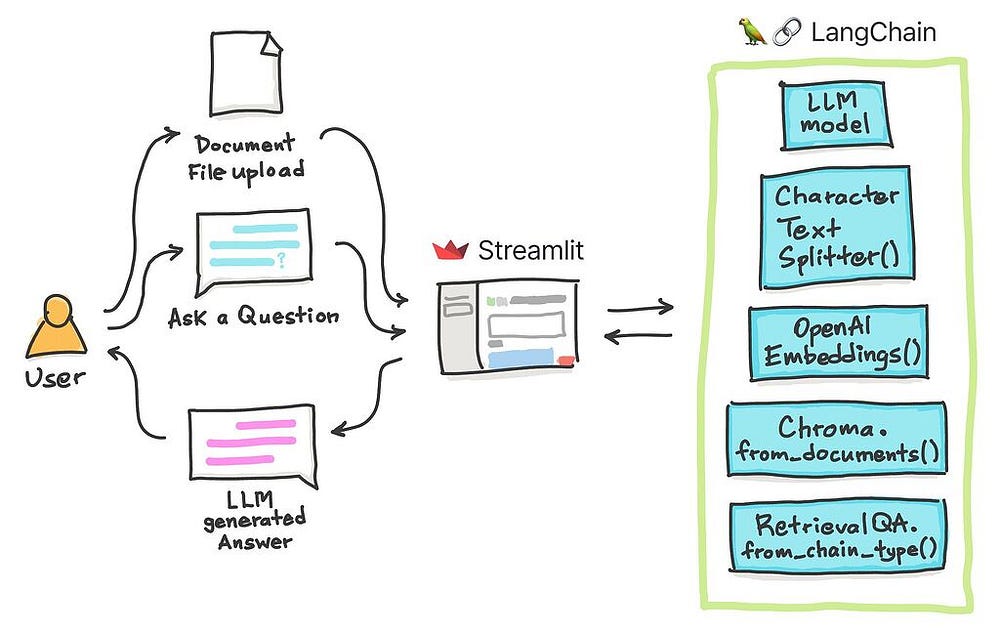
By following these steps, you can seamlessly integrate RAG into your LLM setup and unleash the full potential of retrieval-augmented generation for question answering
Practical Applications of RAG
In business and research
Retrieval-Augmented Generation (RAG) has practical applications in various domains, including business and research. The ability to generate accurate and contextually relevant answers using RAG opens up new possibilities for enhancing customer support, automating content creation, and improving research processes.
Some practical applications of RAG include:
Customer support: RAG can be used to build chatbots or AI assistants that provide personalized assistance across various questions and issues.
Content generation: RAG enables the automation of content creation tasks, such as writing aids or content curation apps.
Education: RAG can serve as a learning assistant, providing explanations and summaries of educational content.
Research: RAG can assist researchers in obtaining relevant information and insights from large document collections.
By leveraging the power of RAG, businesses and researchers can optimize their processes, improve customer experiences, and access valuable information in a more efficient and effective manner.
Success Stories of RAG Implementation: Case Studies
Several businesses and research institutions have successfully implemented Retrieval-Augmented Generation (RAG) in their workflows, achieving significant benefits across various applications. Here are some notable case studies:
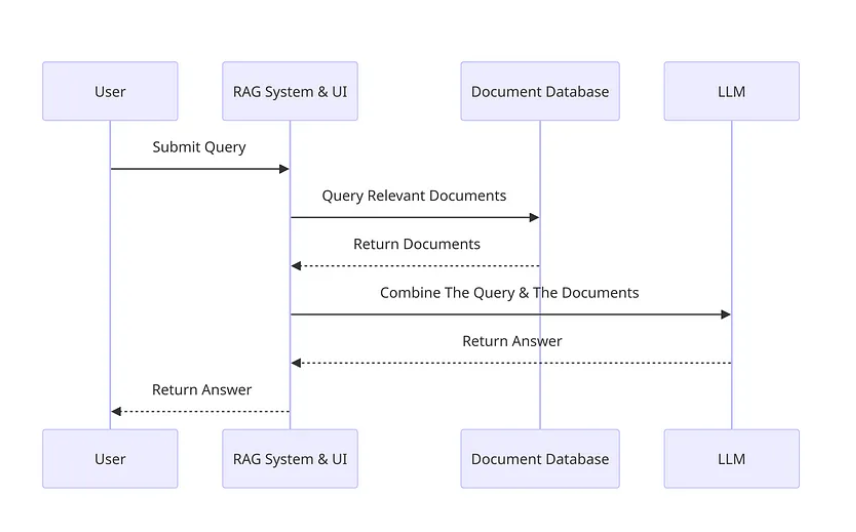
- novita.ai: The LLM API provided by novita.ai has successfully implemented Retrieval Augmented Generation (RAG) system integrating an external document database. This process enhances the accuracy of LLMs by providing relevant context from retrieved documents for generating answers. The system follows a streamlined procedure from querying and processing documents to generating informed responses.
2. Research Institute Y: The research institute integrated RAG into their research processes, enabling researchers to access relevant information more efficiently. RAG streamlined the document retrieval process and provided them with enhanced insights, leading to advancements in their research projects.
3. Content Creation Agency Z: This content creation agency adopted RAG to automate content generation tasks. They experienced increased production speed and improved content quality by leveraging RAG’s ability to generate accurate and contextually relevant responses based on their clients’ requirements.
These case studies highlight the versatility and effectiveness of RAG in various business and research scenarios.
Overcoming Common Pitfalls in RAG Implementation
While implementing Retrieval-Augmented Generation (RAG) systems, there are common pitfalls that need to be addressed to ensure successful implementation. Overcoming these pitfalls is crucial for achieving accurate and efficient question answering capabilities.
Data Quality Issues
Navigating data quality issues is crucial when implementing Retrieval-Augmented Generation (RAG) systems. Data quality directly impacts the accuracy and reliability of the generated answers.

To navigate data quality issues, consider the following:
Ensure relevant data: Collect and curate source documents that contain relevant and reliable information for accurate question answering.
Establish data validation processes: Implement mechanisms to validate the quality and accuracy of the source documents.
Clean and preprocess data: Remove noise, inconsistencies, and irrelevant information from the source documents to improve data quality.
Continuously update and maintain data: Regularly update the source documents to ensure the availability of up-to-date and accurate information.
By navigating data quality issues, organizations can ensure that the RAG system delivers accurate and contextually relevant answers based on high-quality and reliable data.
Ensuring Scalability and Efficiency
Ensuring scalability and efficiency is essential for the successful implementation of Retrieval-Augmented Generation (RAG) systems. Scalability refers to the system’s ability to handle increasing volumes of data and user queries, while efficiency focuses on optimizing computational resources and response time.
To ensure scalability and efficiency in RAG systems, consider the following:
System design: Design the RAG system with scalability and efficiency in mind, considering factors such as distributed computing, parallel processing, and load balancing.
Resource optimization: Optimize computational resources, such as memory and processing power, to achieve optimal performance.
Caching and indexing: Implement caching and indexing mechanisms to facilitate faster document retrieval and minimize computational overhead.
Monitoring and optimization: Continuously monitor and optimize the system’s performance, identifying potential bottlenecks or areas for improvement.
By ensuring scalability and efficiency, organizations can deploy RAG systems that can handle increasing demands and deliver fast and accurate question answering capabilities.
Conclusion
In conclusion, mastering the integration of Retrieval-Augmented Generation (RAG) with Large Language Models opens up a realm of possibilities in enhancing question-answering capabilities and data retrieval efficiency. By understanding the core concepts, components, and implementation steps detailed in this tutorial, you can empower your business or research endeavors with cutting-edge technology. Fine-tuning RAG for optimal performance and navigating common pitfalls are crucial steps in ensuring success. Stay informed about the practical applications and future prospects of RAG to stay ahead in the rapidly evolving landscape of AI technology.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.