




Key Highlights
LoRA (Low-Rank Adapt) is a technique that allows for efficient fine-tuning of large language models (LLMs).
By using lower-rank matrices, LoRA reduces the number of trainable parameters and computational resources required for fine-tuning.
LoRA preserves the integrity of pre-trained model weights and allows for faster adaptation to new tasks or datasets.
It offers benefits such as reduced memory usage, computational efficiency, and the ability to create specialized models for different applications.
LoRA can be combined with other techniques like prefix tuning to further optimize LLM fine-tuning.
The future of LLM optimization with LoRA looks promising, with emerging trends and predictions pointing towards its continued impact on AI and machine learning.
Introduction
Large Language Models (LLMs) such as OpenAI’s GPT-4, Google’s PaLM 2, and the more recent Gemini represent a major breakthrough in artificial intelligence, particularly in natural language processing. These models demonstrate near-human capabilities across various cognitive tasks involving text, images, and videos.
Despite their significant potential, LLMs demand extensive computational resources for training, restricting their development to a handful of major tech companies and elite research institutions. For others to harness the specific capabilities of LLMs, LLM tuning emerges as a vital solution.
LLM tuning involves refining a pre-existing language model to cater to particular tasks or fields. This process builds on the broad language comprehension that the model initially acquired, tailoring it to meet more focused needs. The benefit of LLM tuning is that it avoids the need to train a model from scratch, making it a less resource-intensive and more straightforward approach.

Brief Introduction to LoRA
What is LoRA(Low-Rank Adaptation)
LoRA (Low-Rank Adaptation) is an effective approach to fine-tuning Large Language Models (LLMs) that is democratizing LLM development, enabling smaller organizations and even individual developers to create specialized models. This method allows a specialized LLM to be operated on a single machine, significantly broadening the scope for LLM application within the wider data science community.

How is it used for LLM Fine Tuning
In the LoRA method, the original model weights are kept fixed, and modifications are made to a separate set of weights that are subsequently combined with the original parameters. This approach involves transforming the model parameters into a lower-rank dimension, which reduces the total number of parameters that need to be trained, thus accelerating the tuning process and reducing costs.
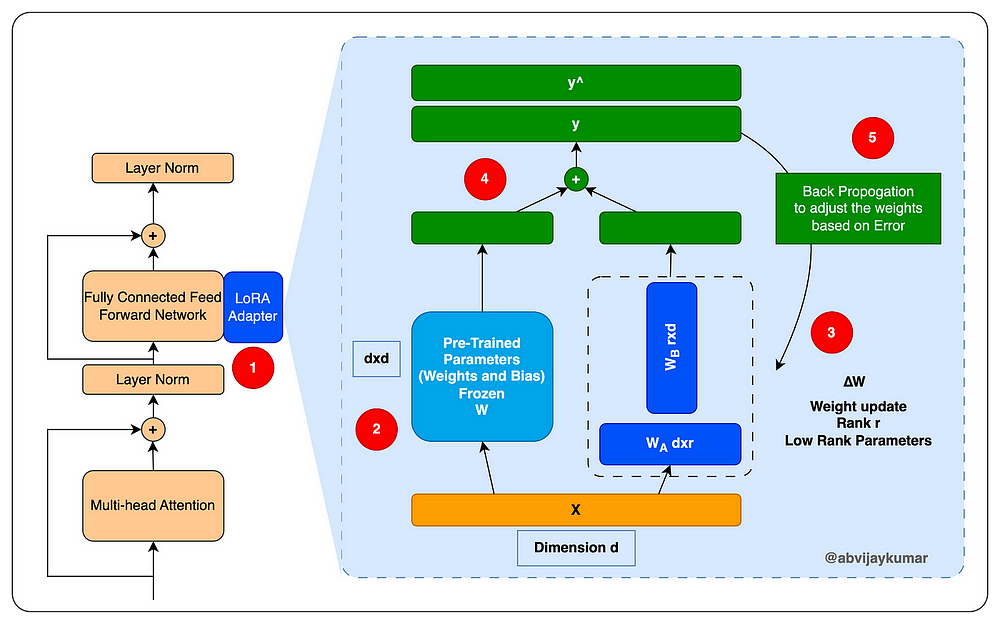
LoRA is particularly advantageous when multiple clients require fine-tuned models for distinct purposes. It facilitates the development of unique sets of weights for each specific application, eliminating the need for multiple separate models.
Advantages of LoRA in Fine-Tuning LLMs
Optimizing the Training and Adaptation Process
LoRA enhances the training and adaptation efficiency of large language models such as OpenAI’s GPT-3 and Meta’s LLaMA by modifying traditional fine-tuning approaches. Rather than updating all the model’s parameters, which can be computationally demanding, LoRA uses low-rank matrices to adjust only a specific subset of the original weights. These matrices are relatively compact, allowing for quicker and more resource-efficient updates.
This technique concentrates on refining the weight matrices in the transformer layers, specifically targeting key parameters for modification. By focusing on selective updates, the process becomes faster and more streamlined, enabling the model to adapt to new tasks or data sets without the extensive retraining required by conventional methods.
Preservation of Pre-trained Model Weights
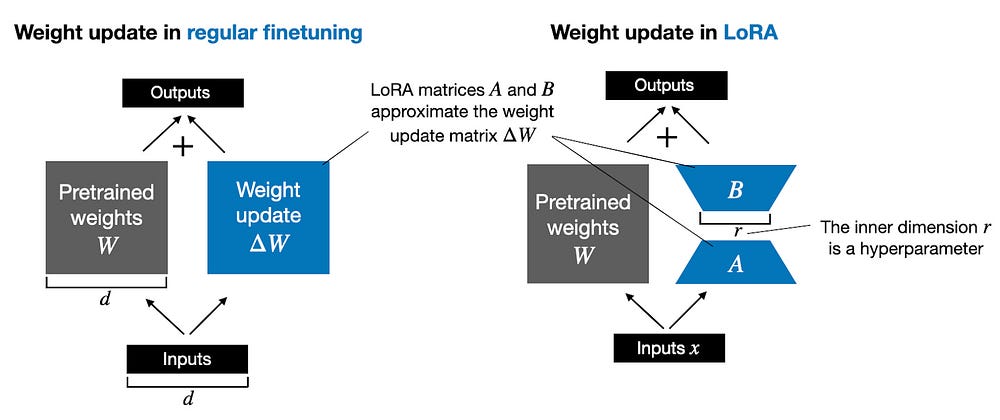
LoRA maintains the integrity of pre-trained model weights, providing a key benefit over traditional fine-tuning methods. Typically, fine-tuning involves altering all model weights, risking the loss of the broad knowledge the model initially acquired. However, LoRA’s method of selective weight updating through low-rank matrices helps preserve the essential structure and knowledge of the pre-trained model.
This preservation is essential for retaining the model’s comprehensive understanding and capabilities while enabling targeted adaptations to specific tasks or datasets. It ensures that the fine-tuned model maintains the original model’s strengths, like its grasp of language and context, while also acquiring new skills or enhancing performance in specific areas.
How to Implement LoRA for LLMs
Preparing Your LLM for LoRA
Preparing your large language model (LLM) for LoRA involves understanding the architecture of the language model and the training procedure. This step is crucial to ensure a solid foundation for implementing LoRA.
Firstly, you need to have a clear understanding of the specific LLM architecture you are working with. This includes understanding the number of layers, the size of each layer, and the overall structure of the model.
Next, you need to familiarize yourself with the training procedure for the LLM. This includes understanding the data preprocessing steps, the optimizer used, and the hyperparameters that are typically tuned during training.
The Process of Applying LoRA to LLMs
The process of applying LoRA to LLMs involves incorporating LoRA layers into the model and specifying the necessary parameters. This process allows for efficient and effective model adaptation without the need for retraining the entire model.
Firstly, LoRA layers are added to the LLM model during the fine-tuning process. These layers include the necessary lower-rank matrices that will be used for updating a subset of the original model’s weights.
Next, the learning rate and other hyperparameters are specified to ensure optimal model adaptation. The learning rate determines the rate at which the model adapts to new data or tasks.
Finally, the fine-tuning process begins, where the model is trained using the specified LoRA weights and learning rate. This process allows the model to adapt to new tasks or datasets while preserving the general language understanding acquired during the initial training phase.
Monitoring and Adjusting LoRA Parameters
Monitoring and adjusting LoRA parameters is crucial to optimize the fine-tuning process of large language models (LLMs). These parameters include the scaling factor, learning rate, and weight update mechanism.
The scaling factor determines the impact of the LoRA weights on the overall model adaptation. Monitoring and adjusting the scaling factor allows for fine-tuning the model to specific requirements and achieving the desired level of adaptation.
The learning rate determines the rate at which the model adapts to new tasks or datasets. Monitoring and adjusting the learning rate ensures that the model adapts effectively without overfitting or underfitting.
The weight update mechanism determines how the LoRA weights are updated during the fine-tuning process. Monitoring and adjusting the weight update mechanism allows for optimizing the model’s performance and achieving the desired level of adaptation.
Practical Examples of LoRA in Action
LoRA has proven to be a valuable technique in various practical applications, especially in the field of generative AI and natural language processing (NLP). Here are a few examples of how LoRA is being used in action:
Case Study: Enhancing Chatbots with LoRA
One practical example of LoRA in action is the enhancement of LLM through the use of LoRA. The LoRA approach enables chatbots to generate more contextually relevant and human-like responses, leading to a more engaging and effective user experience. This enhances the overall performance and usability of chatbot applications, making them more valuable in various industries.
Here is a perfect example of fine-tuning LLM provided by novita.ai:

By applying LoRA to Chat-completion by novita.ai, developers can improve the accuracy and relevance of chatbot responses. LoRA allows for the adaptation of the chatbot model to specific domains or tasks while preserving the general language understanding acquired during the initial training phase.
Success Story: Improving Translation Accuracy Using LoRA
Another success story of LoRA in action is the improvement of translation accuracy in natural language processing (NLP) applications. Translation models play a crucial role in multilingual communication and language localization.
By using LoRA to fine-tune translation models, developers can achieve higher accuracy and fluency in translated text. LoRA allows for the adaptation of the translation model to specific languages or domains while preserving the general language understanding acquired during the initial training phase.
The use of the LoRA technique enhances the translation accuracy of NLP applications, making them more reliable and effective in providing accurate translations. This has significant implications for multilingual communication in various industries, such as e-commerce, travel, and global business operations.
The Future of LLM Optimization with LoRA
The future of large language model (LLM) optimization with LoRA looks promising, with emerging trends and predictions pointing towards its continued impact on AI and machine learning.
Emerging trends in LLM development include the exploration of stable diffusion models and the development of stable diffusion XL models that leverage the power of LoRA for efficient fine-tuning.
Emerging Trends in LoRA and LLM Development
The field of large language model (LLM) development is continuously evolving, and there are several emerging trends related to LoRA and LLM optimization.
One emerging trend is the exploration of stable diffusion models combined with LoRA. Stable diffusion models leverage LoRA to enhance style specialization, character consistency, and quality improvements in generative AI applications.
Another emerging trend is the development of foundation models that serve as the starting point for fine-tuning LLMs. Foundation models provide a strong base for further adaptation and specialization using techniques like LoRA.
Predictions for LoRA’s Impact on AI and Machine Learning
LoRA’s impact on AI and machine learning is expected to be significant in the coming years. Predictions for LoRA’s future impact include:
Accessible LLMs: LoRA is expected to make LLMs more accessible to a broader range of users and organizations, enabling them to leverage the power of large language models for various applications.
Domain-Specific Fine-Tuning: LoRA’s efficiency in fine-tuning LLMs will lead to advancements in domain-specific fine-tuning, allowing for highly specialized models tailored to specific industries or tasks.
Advancements in Adaptation: LoRA will continue to drive advancements in LLM adaptation, enabling faster and more efficient model adaptation to new tasks, datasets, and domains.
Conclusion
In conclusion, LoRA (Low-Rank Adaptation) presents a cutting-edge approach to fine-tuning Large Language Models (LLMs). Its advantages include reduced computational requirements and the preservation of pre-trained model weights. By implementing LoRA, you can enhance LLM performance efficiently. Understanding the process and monitoring parameters is key to successful implementation. Practical examples, such as improving chatbots and translation accuracy, showcase the effectiveness of LoRA. Overcoming challenges and optimizing for different LLM architectures will shape the future of AI and machine learning. Stay ahead by leveraging LoRA for advanced LLM optimization in the rapidly evolving landscape of artificial intelligence and natural language processing.
Frequently Asked Questions
What Makes LoRA Different from Other Fine-Tuning Techniques?
LoRA distinguishes itself from other fine-tuning techniques by selectively updating a subset of the original model’s weights through the use of lower-rank matrices. This approach reduces the number of trainable parameters and computational resources required for fine-tuning, making it more efficient and feasible for large language models.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.