




Introduction
In the rapidly evolving landscape of artificial intelligence, the interplay between large language models (LLMs) and their smaller counterparts is a narrative of synergy and innovation. The towering capabilities of LLMs like GPT-3 and GPT-4, while awe-inspiring, are encased in a fortress of limitations — limited accessibility of model weights, immense computational demands, and the constraints of in-context learning (ICL).
Yet, within these confines lies a chink, an opportunity for small models to step in as plug-ins, offering a bridge to more personalized and efficient applications. This blog delves into the necessity and impact of integrating small models as plug-ins within the expansive realms of LLMs, exploring the concept of Super In-Context Learning (SuperICL) and its real-world ramifications.
Understanding LLMs and Smaller Models
The Differences between LLMs and Smaller Models
A Large Language Model is a sophisticated AI system designed to process and understand large volumes of natural language data. LLMs typically have a vast number of parameters, often ranging from hundreds of millions to billions. This allows them to capture intricate patterns and relationships within language, enabling advanced capabilities such as language translation, text summarization, question-answering, and content generation. LLMs are trained on large datasets and can exhibit complex behaviors and “emergent abilities” as they scale up in size, although the latter concept is subject to debate, as discussed in the Stanford research.
In contrast, smaller models have fewer parameters and are less complex. They may be more limited in their capabilities and the range of tasks they can perform effectively. Smaller models are typically used for more specific or less complex tasks due to their lower computational requirements and smaller dataset needs. While they can be very efficient and effective for certain applications, they generally do not possess the same level of nuanced understanding or the ability to handle a wide variety of language tasks as LLMs.
What Are the Best Open-Source LLMs?
BERT: Developed by Google, BERT is a pioneering LLM known for its transformative impact on natural language processing, utilized globally in Google Search and inspiring numerous specialized models.
Falcon 180B: The UAE’s Technology Innovation Institute’s LLM with 180 billion parameters, excelling in text generation and processing, with a smaller version, Falcon-40B, also recognized for language understanding.
GPT-NeoX and GPT-J: EleutherAI’s open-source LLMs with 20 billion and 6 billion parameters, respectively, offering high performance across domains and promoting AI democratization.
LLaMA 3: Meta AI’s versatile LLM, ranging from 7 to 70 billion parameters, optimized for natural language generation and customizable through an open-source license, with APIs available for developers. Companies, e.g. Novita AI, usually offer LLaMA 3 APIs for AI startups.
BLOOM: An open-source LLM with 176 billion parameters, a collaborative effort by Hugging Face, designed for multilingual and programming language text generation, prioritizing transparency and accessibility.
Vicuna 13-B: Fine-tuned from LLaMa 13B, this open-source conversational model is adept at handling extended dialogues in chatbot applications across industries, showcasing advanced conversational AI capabilities.
Why Do We Need Small Models As Plug-Ins for Large Language Models?
Limited Accessibility of Model Weights
LLMs like GPT-3 and GPT-4 are powerful tools for a variety of natural language processing (NLP) tasks. However, the actual weight parameters of these models are typically not shared publicly due to intellectual property and security concerns.
Without access to the model weights, it’s not possible to perform in-house fine-tuning where the model’s parameters are adjusted to better suit a specific task or dataset.
Immense Model Sizes
LLMs are typically very large, with billions of parameters, which makes them resource-intensive. The hardware requirements for training or even fine-tuning such models are beyond the reach of most individuals and smaller organizations.
The large size also means that transferring these models to different hardware or using them in environments with limited computational power is challenging.
In-Context Learning (ICL) Limitations
ICL is a technique where a few labeled examples are provided alongside the input to help the model make predictions. This method allows the model to learn from the context provided by the examples.
However, ICL is limited by the context length that the LLM can process. If the context is too long, it may exceed the model’s capacity, and the model won’t be able to effectively utilize all the provided examples.
This limitation is particularly problematic when there is a large amount of supervised data available, as ICL can only use a small subset of it due to the context length constraint.
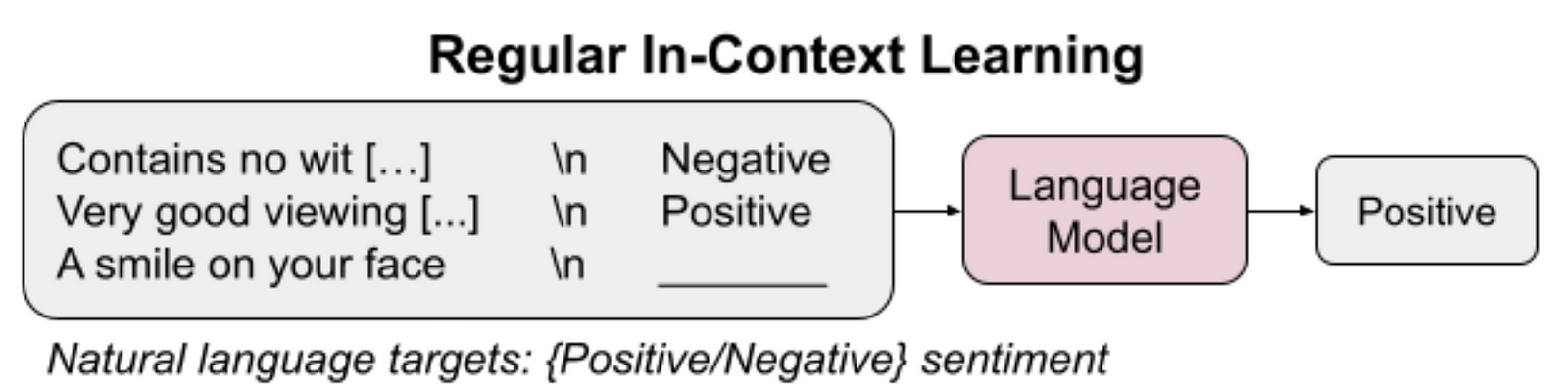
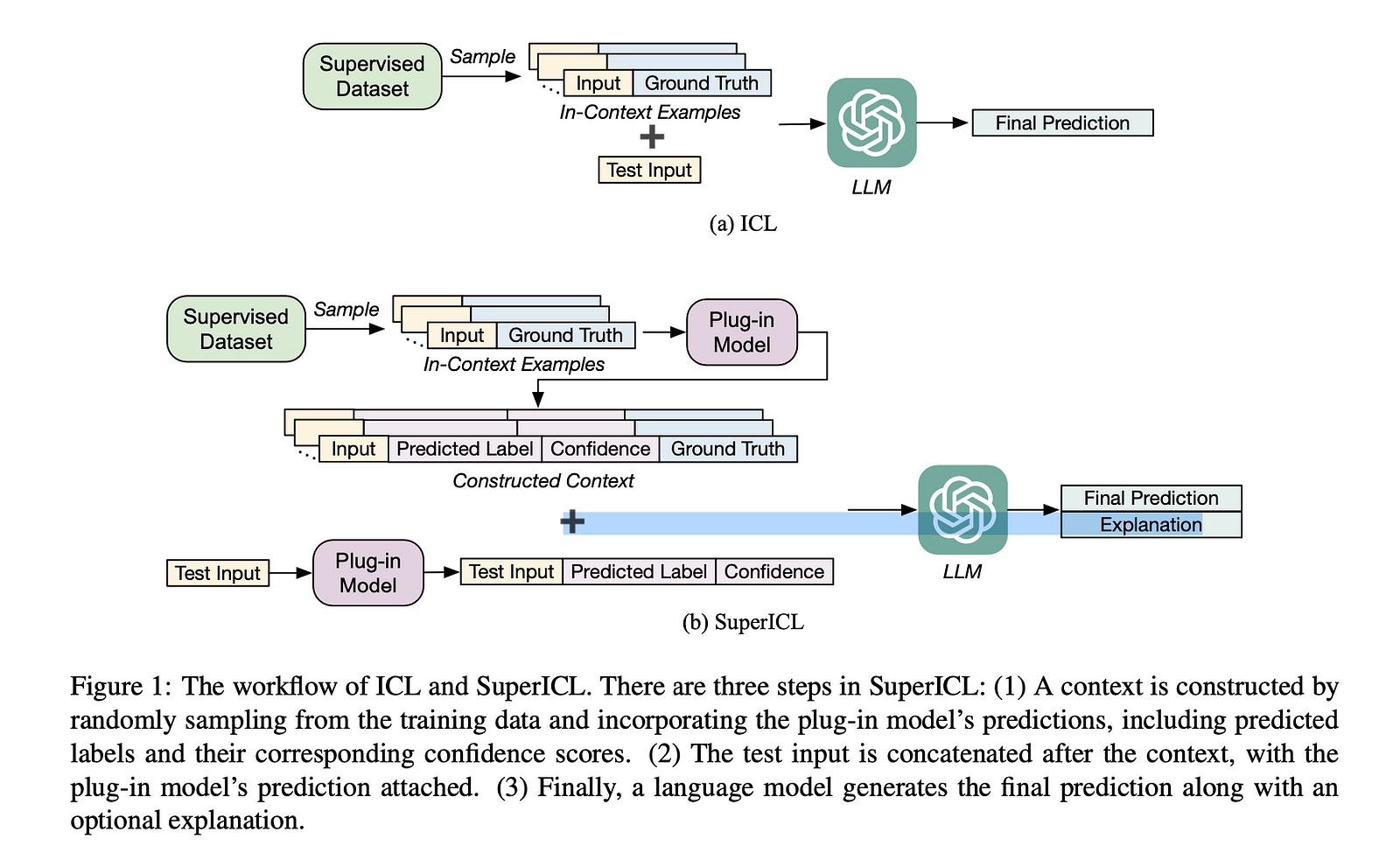
To address these issues, some scholars propose Super In-Context Learning (SuperICL), which combines the strengths of LLMs with locally fine-tuned smaller models. The smaller models, or plug-ins, are fine-tuned on task-specific data and provide a bridge between the general capabilities of the LLM and the specific requirements of the task at hand. This approach allows for more effective knowledge transfer and improved performance on supervised tasks, overcoming the limitations of ICL and the challenges associated with the size and inaccessibility of LLMs.
How Do People Find out Small Models Are Valuable Plug-Ins for Large Language Models?
In this section, we are going to discuss the paper titled “Small Models are Valuable Plug-ins for Large Language Models” by Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu and Julian McAuley from University of California, San Diego and Microsoft. Like always, if the research details do not interest you, feel free to skip to the next section.
Method
Based on the recognition of LLMs’ limitations, which we have discussed in the previous section, the authors propose SuperICL to combine LLMs with locally fine-tuned smaller plug-in models. The plug-in model is first fine-tuned on the task-specific supervised dataset. It then makes predictions with confidence scores on the training examples from this dataset. These predictions are provided as context to the LLM along with the test input. The LLM utilizes this context to make the final prediction and can optionally generate an explanation for its reasoning.
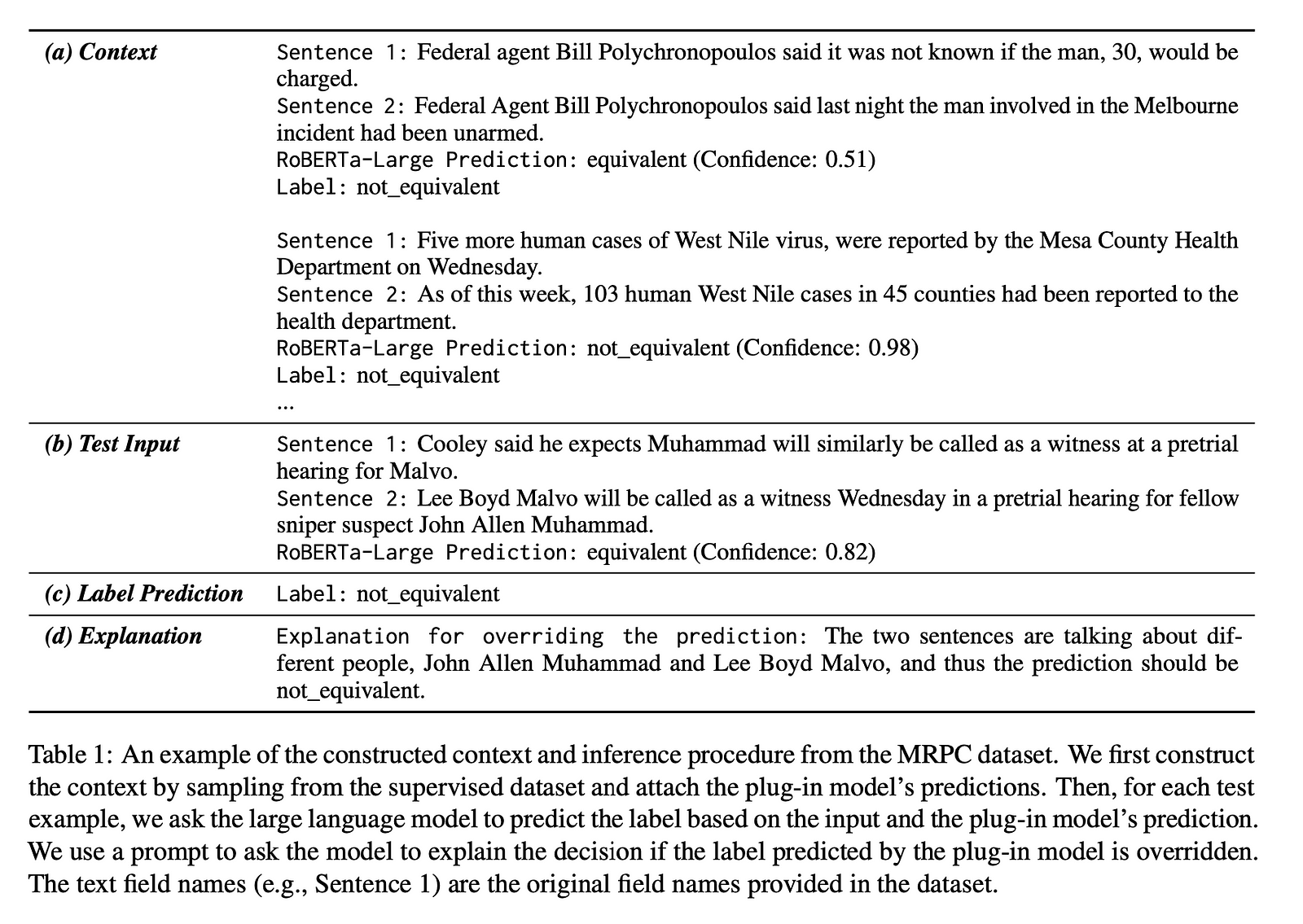
Experiment Design
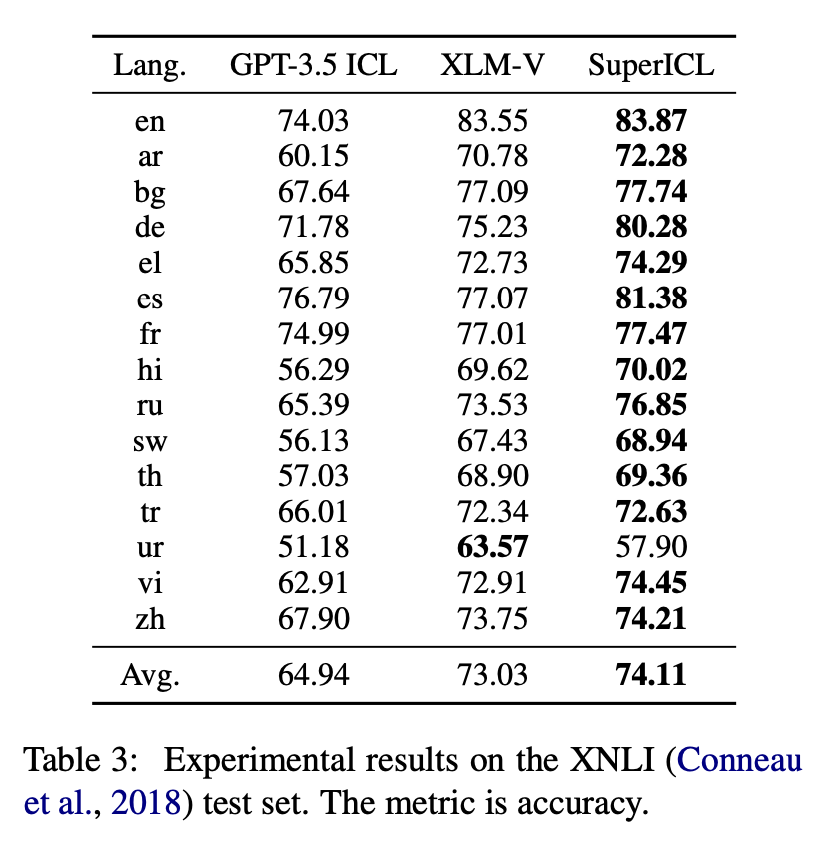
They evaluate on the GLUE benchmark for natural language understanding tasks and on XNLI for zero-shot cross-lingual transfer. GPT-3.5 is used as the LLM and RoBERTa-Large/XLM-R as plug-in models. SuperICL is compared against baselines of ICL with GPT-3.5 and using only the plug-in models.
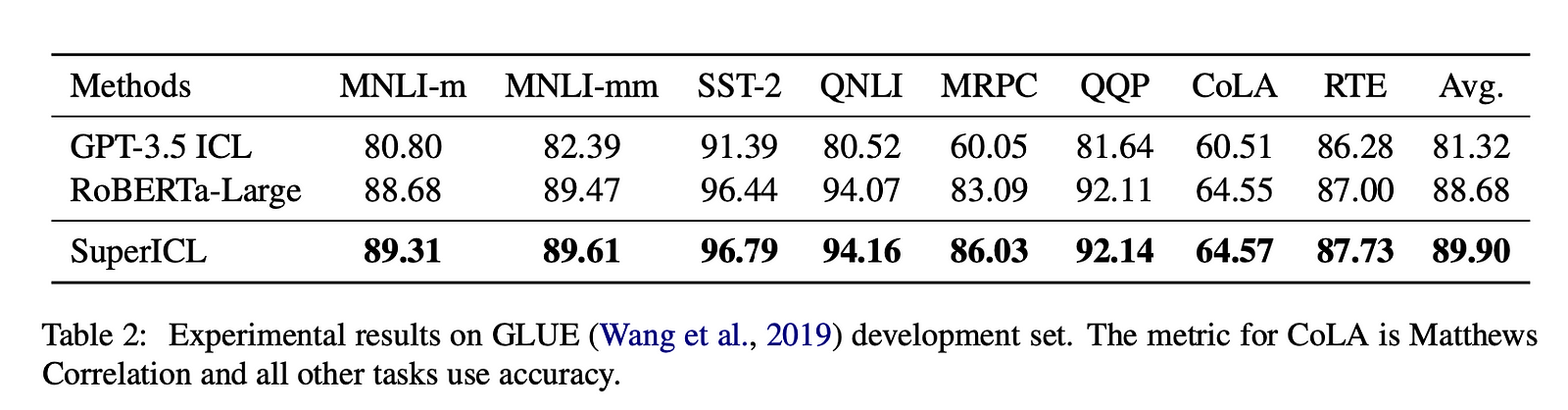
Results
SuperICL outperforms both GPT-3.5 ICL and the plug-in models individually on the GLUE benchmark. On the XNLI dataset, SuperICL improves over XLM-R for most languages, demonstrating effective zero-shot transfer. An ablation study shows the importance of each component in the SuperICL approach.
Wrap-Up
SuperICL achieves superior performance by combining the strengths of LLMs and smaller plug-in models fine-tuned on task data. It addresses the instability issue of regular ICL by separating language understanding from task-specific knowledge absorption. Additionally, SuperICL enhances the capabilities of smaller models like extending their multilinguality coverage. It also provides interpretability by allowing the LLM to generate explanations when overriding plug-in predictions.
Real-life Cases of Small Models As Plug-Ins for Large Language Models
Customized Customer Service Chatbots
Small, domain-specific models can be fine-tuned to understand the terminology and context of a particular industry and then used as plug-ins in a large chatbot framework to provide more accurate and relevant responses.
Medical Diagnosis Assistance
A small model trained on medical records and literature can act as a plug-in for an LLM to assist doctors in diagnosing conditions, suggesting treatments, and interpreting medical tests more accurately.
Legal Document Analysis
Small models fine-tuned on legal documents can be used to enhance LLMs in parsing and understanding legal contracts, providing summaries, and highlighting potential issues or clauses.
Language Translation
For low-resource languages, small models can be trained on the available data and then used as plug-ins in LLMs to improve translation quality and handle nuances better.
Educational Tools
Small models tailored to educational content can be integrated with LLMs to create intelligent tutoring systems that provide personalized feedback and explanations to students.
Content Moderation
Small models trained to detect specific types of content (e.g., hate speech, explicit content) can be used to enhance the capabilities of LLMs in moderating user-generated content on social media platforms.
Healthcare Monitoring
Small models trained to recognize patterns in patient data can be used to provide early warnings or insights into potential health issues when integrated with an LLM that can process and analyze larger datasets.
These applications demonstrate how the combination of specialized knowledge from small models with the broad understanding of LLMs can lead to more efficient, accurate, and tailored solutions in various professional and personal contexts.
How to Run Codes for SuperICL
These codes presented below are quoted from https://github.com/JetRunner/SuperICL?tab=readme-ov-file. You can find all the Python scripts mentioned below with this link.
Setup Process
1 Install the Necessary Packages: Use the pip package manager to install all the required packages listed in the requirements.txt file.
pip install -r requirements.txt
2 Configure the OpenAI API Key:
Copy the example configuration file to create your own configuration file:
cp api_config_example.py api_config.py.Edit the newly created
api_config.pyfile using a text editor likevito insert your OpenAI API key.
Running the Code for Different Tasks
1 GLUE Benchmark:
Execute the
run_glue.pyscript with the specified parameters to run the model on the GLUE benchmark.Include the
--model_pathpointing to the location of the model,--model_namewith the model identifier, and the--datasetspecifying the GLUE task.To enable explanations for model predictions, add the
--explanationflag.
python run_glue.py \
--model_path roberta-large-mnli \
--model_name RoBERTa-Large \
--dataset mnli-m \
--explanation # Add this flag for explanations
- For all supported tasks, refer to the provided doc.
2 XNLI Benchmark:
Run the
run_xnli.pyscript for cross-lingual natural language inference tasks with the specified parameters.Specify the
--model_pathto the model's directory,--model_namewith the model's name, and--langto list the languages included in the dataset.
python run_xnli.py \
--model_path /path/to/model \
--model_name XLM-V \
--lang en,ar,bg,de,el,es,fr,hi,ru,sw,th,tr,ur,vi,zh
Additional Information
For all available parameters for the scripts, refer to the code repository.
Citation
If you use this work in your research, please cite it as follows:
@article{xu2023small,
title={Small Models are Valuable Plug-ins for Large Language Models},
author={Xu, Canwen and Xu, Yichong and Wang, Shuohang and Liu, Yang and Zhu, Chenguang and McAuley, Julian},
journal={arXiv preprint arXiv:2305.08848},
year={2023}
}
Limitations of Small Models As Plug-Ins for Large Language Models
Dependency on plug-in model performance
The overall performance of SuperICL is still reliant on the quality of the locally fine-tuned plug-in model. If the plug-in model performs poorly on the task, it may limit SuperICL’s effectiveness.
Computational cost
Fine-tuning the plug-in model requires access to sufficient computational resources. For very large supervised datasets, this fine-tuning may become prohibitively expensive for smaller research groups or individuals.
Task generalizability
The experiments focus on natural language understanding tasks in the GLUE benchmark. While promising, more evaluation is needed to assess SuperICL’s effectiveness on other NLP tasks like generation, summarization, translation etc.
Cross-task transfer
It’s unclear how well a single plug-in model fine-tuned on one task can generalize and provide effective context for an entirely different task when used with SuperICL.
Multilinguality limits
While SuperICL enhances multilinguality, its cross-lingual abilities are still fundamentally limited by the original multilingual capabilities of the plug-in model like XLM-R.
Conclusion
The integration of small models as plug-ins with LLMs, as demonstrated by SuperICL, offers a compelling solution to the inherent limitations of large-scale AI. By augmenting the capabilities of LLMs, we pave the way for more nuanced, efficient, and broadly applicable AI systems. Yet, challenges such as dependency on plug-in performance, computational costs, and task generalizability persist, urging a balanced approach to harnessing this synergy.
Stay tuned to explore the newest findings of AI academia!
Originally published at Novita AI
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.