




Introduction
What will happen when large language models encode clinical knowledge? In this article, we will discuss the theoretical applications of LLMs in the medical domain, the constraints that prohibit their use, the consequences of LLMs encoding clinical knowledge, current open-source medical LLMs and the way to train your own medical LLM. Keep reading to unlock the potential of LLMs in the medical field!
How Can LLMs Possibly Help With Clinical Tasks?

Enhanced Data Interpretation
Large Language Models (LLMs) can significantly augment clinical tasks by providing advanced natural language understanding capabilities. They can interpret complex medical texts, such as Electronic Health Records (EHRs) and radiology reports, to extract crucial information that aids in diagnosis and treatment planning.
Automated Medical Coding
LLMs can streamline the process of medical coding by accurately identifying and categorizing patient conditions and procedures from clinical narratives, thereby reducing the administrative burden on healthcare professionals.
Clinical Decision Support
By analyzing patterns and trends within large datasets, LLMs can offer evidence-based recommendations, assisting clinicians in making informed decisions. They can also keep up-to-date with the latest medical research, providing real-time updates to clinical guidelines.
Drug Interaction Checking
LLMs can be trained to understand and predict potential drug interactions and contraindications by analyzing patient medication lists and medical literature, thereby enhancing patient safety.
Triage and Symptom Checker
In telemedicine and remote healthcare settings, LLMs can act as initial assessors of patient symptoms, providing preliminary diagnoses and directing patients to the appropriate level of care.
What Are the Reasons That Restrain General LLM’s Applications in the Medical Domain?

Specialized Knowledge Requirement
Medical language is highly technical and context-dependent. General LLMs may lack the nuanced understanding of medical terminology and clinical concepts, leading to inaccuracies in interpretation.
Data Privacy and Security Concerns
Clinical data is sensitive and subject to strict regulatory protections. The use of LLMs in healthcare must ensure robust data encryption and comply with healthcare-specific regulations such as HIPAA.
Risk of Misinformation
LLMs trained on diverse datasets may inadvertently generate misinformation or outdated medical advice, which can have serious consequences in a clinical setting.
Lack of Explainability
In medical applications, it is crucial to understand the reasoning behind a model’s decision. General LLMs often operate as “black boxes,” making it difficult to explain and trust their outputs in life-critical situations.
Ethical Considerations
The use of LLMs in medicine raises ethical questions about data bias, algorithmic fairness, and the potential for unintended consequences on patient care.
Computational Resource Intensity
Training and deploying large-scale LLMs requires significant computational resources, which may not be feasible for all healthcare providers, especially in resource-constrained environments.
Continuous Monitoring and Updating
Medical knowledge evolves rapidly, necessitating ongoing monitoring and updating of LLMs to ensure their knowledge base remains current. This requires a dedicated team of experts and a sustainable process for model updates.
Regulatory Approval and Validation
LLMs used in healthcare must undergo rigorous validation and receive approval from regulatory bodies to ensure they meet the required standards for safety and efficacy in medical practice.
Is It Possible to Train LLMs to Be Good Doctors?
Authors of the paper “Large Language Models Encode Clinical Knowledge” probably will answer, “It is promising, but it’s complicated.” As always, if you are not interested in the nerdy academic discussion below, just take this conclusion and jump to the next section: The article underscores the promise of LLMs in encoding medical knowledge and the significant challenges that must be overcome to ensure their safe and effective use in clinical settings.
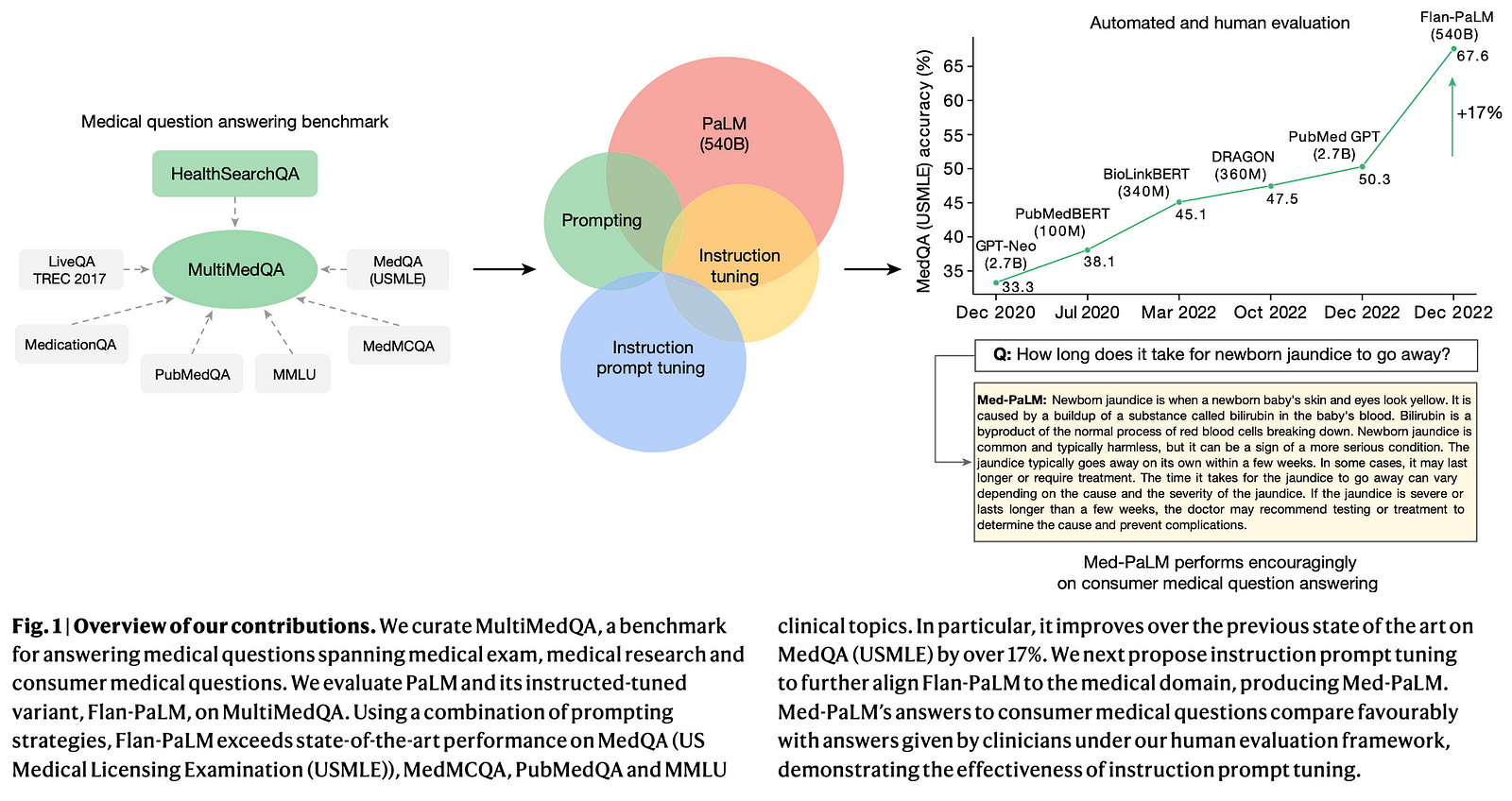
Background
Large language models (LLMs) have shown impressive performance across various tasks but their effectiveness in clinical settings, where safety is critical, is not well-established.
The authors highlight the need for a comprehensive benchmark to assess these models’ performance in answering medical questions accurately and safely.
MultiMedQA Benchmark
The researchers introduce MultiMedQA, a benchmark that combines six existing medical question-answering datasets and a new dataset called HealthSearchQA, which includes commonly searched online medical questions.
This benchmark is designed to evaluate models on multiple aspects, including factuality, comprehension, reasoning, potential harm, and bias.
Model Evaluation
The authors evaluate a 540-billion parameter LLM called PaLM and its instruction-tuned variant, Flan-PaLM, on the MultiMedQA benchmark.
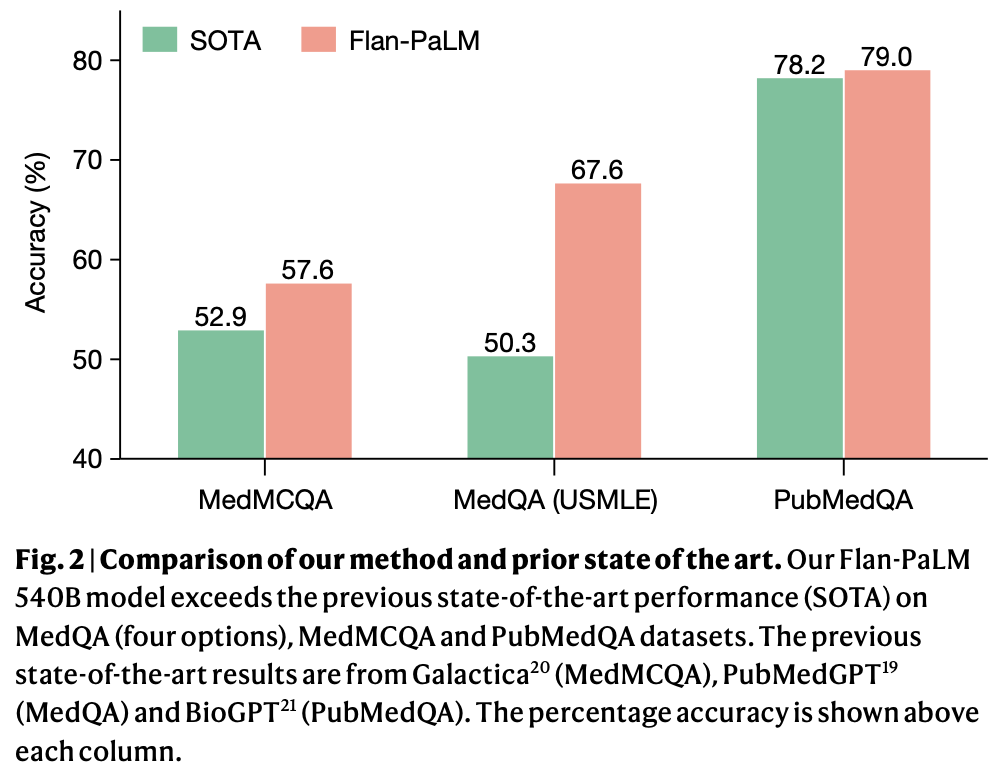
Using various prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on multiple-choice medical question datasets, including a significant 17% improvement on MedQA, which contains US Medical Licensing Exam-style questions.
Human Evaluation Framework
The researchers propose a human evaluation framework to assess model answers along multiple dimensions, including alignment with scientific consensus, potential for harm, and presence of bias.
A panel of clinicians evaluated the models’ performance, revealing key gaps even in high-performing models.
Instruction Prompt Tuning
To address the gaps identified, the authors introduce “instruction prompt tuning,” a method to align LLMs more closely with the medical domain using a few exemplars.
The resulting model, Med-PaLM, shows improved performance and safety but still falls short of clinician standards.
Key Findings
The study finds that model scale and instruction prompt tuning improve comprehension, knowledge recall, and reasoning.
While LLMs show potential for use in medicine, human evaluations reveal limitations, emphasizing the need for robust evaluation frameworks and method development to create safe and helpful LLMs for clinical applications.
Limitations and Future Work
The authors acknowledge that MultiMedQA, while diverse, is not exhaustive and plan to expand it to include more medical and scientific domains and multilingual evaluations.
They also outline the need for LLMs to ground responses in authoritative medical sources, detect and communicate uncertainty, respond in multiple languages, and align better with medical safety requirements.
Improving human evaluation methods and considering fairness and equity in the use of LLMs in healthcare are highlighted as important future research directions.
Are There Any Open-Source Medical LLMs That I Can Use?
Med_Gemini-[2D,3D,Polygenic]: Enhancing the Multimodal Medical Functions of Gemini
BioBERT: A biomedical language representation model designed for biomedical text mining tasks
BioMistral: An open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central
MEDITRON-70B: A suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain
PMC-LLaMA:A powerful, open-source language model specifically designed for medicine applications
MEDALPACA: An Open-Source Collection of Medical Conversational AI Models and Training Data
BioMedLM-PubMedGPT: A 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles
Med-PaLM: A large language model from Google Research, designed for the medical domain
PubMedBERT: A pretrained language model specifically designed for biomedical natural language processing tasks
How Can I Train My Own Medical LLM?
Training an adept medical LLM demands a synergistic approach that combines the foundational strengths of LLM APIs with specialized domain knowledge and rigorous data science practices. Put simply, it requires to enable large language models to encode clinical knowledge. After reading these guidelines, you can have a general idea of what steps you need to go through if you want to train your own medical LLM.
Step 1 Leverage Existing LLM APIs for Prototyping
Commence by engaging with established LLM APIs to prototype and benchmark your medical language processing tasks. LLM APIs such as those provided by Novita AI offer access to models that have been pre-trained on extensive corpora and can be adapted to specialized domains through further fine-tuning.
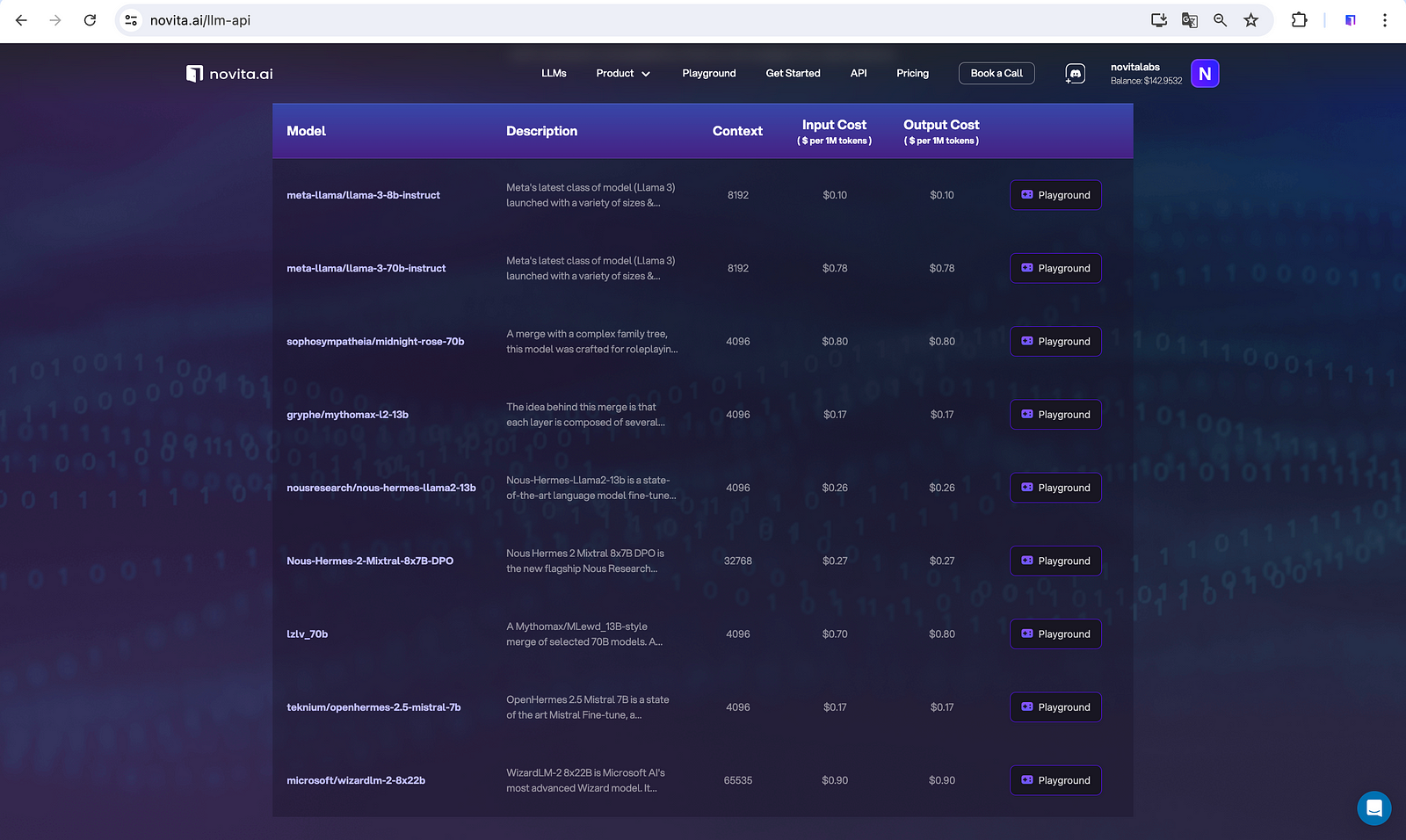
Before integrating APIs, Novita AI also allows you to see the performances of available LLMs so that you can decide which ones are up to your expectations for your own medical LLM.
Step 2 Comprehensive Domain Understanding
Attain an exhaustive comprehension of the medical domain, including the mastery of clinical terminologies, diagnostic procedures, and the regulatory landscape governing medical data. This expertise is indispensable for curating a dataset that is pertinent and rich enough to train a competent medical LLM.
Step 3 Rigorous Data Curation and Annotation
Source a diverse and representative dataset of medical literature, de-identified Electronic Health Records (EHRs), and clinical narratives. Implement rigorous data preprocessing steps, including tokenization, part-of-speech tagging, and entity recognition, to structure the data for model training. Annotation should be performed by domain experts to ensure the dataset is accurately labeled for supervised learning tasks.
Step 4 Customized Pretraining on Medical Datasets
Employ the foundational architecture provided by an LLM API as a starting point. Subsequently, conduct a domain-specific pretraining phase by further conditioning the model on your curated medical dataset. This process, known as domain-adaptive pretraining (DAPT), facilitates the model’s acquisition of medical jargon and clinical reasoning skills.
Step 5 Fine-tuning with Specialized Data
Utilize the LLM API’s fine-tuning capabilities to adapt the model to specific medical tasks such as diagnosis prediction, treatment recommendation, or information extraction from radiology reports. Fine-tuning with a task-specific dataset enhances the model’s ability to deliver accurate and contextually relevant responses.
Step 6 Model Evaluation and Hyperparameter Optimization
Implement a battery of quantitative evaluations, including precision, recall, F1 score, and receiver operating characteristic (ROC) analysis, to assess the model’s performance. Engage in hyperparameter optimization using techniques like grid search or Bayesian optimization to enhance the model’s predictive accuracy and generalizability.
Step 7 Continuous Model Refinement and Knowledge Updating
Institute a protocol for continuous learning and model updating to incorporate the latest medical insights and research findings. This ensures the model’s knowledge base remains current and relevant, adapting to the evolving medical landscape.
Step 8 Address Ethical and Compliance Issues
Ensure the training process adheres to ethical standards and complies with healthcare regulations such as the Health Insurance Portability and Accountability Act (HIPAA). Implement robust data protection measures, and maintain transparency in model decision-making to uphold patient privacy and trust.
Conclusion
As we conclude our exploration of LLMs in clinical tasks, it’s clear that while the technology holds immense promise, it’s not without its challenges. The blog has shed light on the innovative ways LLMs can assist in various medical tasks, from automated medical coding to triage and symptom checking. However, the path to integrating these models into clinical practice is lined with hurdles such as specialized knowledge requirements, data privacy concerns, and the need for continuous monitoring and regulatory approval.
Harnessing the full potential of Large Language Models (LLMs) in the medical field is a collaborative endeavor that calls for pooled wisdom and expertise. Whether you choose to delve into existing medical LLM frameworks or embark on crafting a bespoke model tailored to your needs, the journey is both exciting and rewarding. Embrace the synergy of collective intelligence as you unlock the transformative capabilities of LLMs in healthcare.
Originally published at Novita AI
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.